Developer News
Should We Even Have :closed?
For the past few months, I’ve been writing a lot of entries on pseudo-selectors in CSS, like ::picker() or ::checkmark. And, in the process, I noticed I tend to use the :open pseudo-selector a lot in my examples — and in my work in general.
Borrowing words from the fine author of the :open entry in the Almanac:
The CSS :open pseudo-selector targets elements that support open and closed states — such as the <details> and <select> elements — and selects them in their open state.
So, given this:
details:open { background: lightblue; color: darkred; }We expect that the <details> element gets a light blue background and dark red text when it is in an open state (everywhere but Safari at the time I’m writing this):
CodePen Embed FallbackBut what if we want to select the “closed” state instead? That’s what we have the:closed pseudo-class for, right? It’s supposed to match an element’s closed state. I say, supposed because it’s not specced yet.
But does it need to be specced at all? I only ask because we can still target an element’s closed state without it using :not():
/* When details is _not_ open, but closed */ details:not(:open) { /* ... */ }So, again: do we really need a :closed pseudo-class? The answer may surprise you! (Just kidding, this isn’t that sort of article…)
Some backgroundTalks surrounding :open started in May 2022 when Mason Freed raised the issue of adding :open (which was also considered being named :top-layer at the time) to target elements in the top layer (like popups):
Today, the OpenUI WC similarly resolved to add a :top-layer pseudo class that should apply to (at least) elements using the Popup API which are currently in the top layer. The intention for the naming and behavior, though, was that this pseudo class should also be general purpose. It should match any type of element in the top layer, including modal <dialog>, fullscreen elements, and ::backdrop pseudo elements.
This sparked discourse on whether the name of the pseudo-element targeting the top layer of any type of element (e.g., popups, pickers, etc.) should either be :open or :top-layer. I, for one, was thrilled when the CSSWG eventually decided on :open in August 2022. The name makes a lot more sense to me because “open” assumes something in the top layer.
To :close or :not(:open)?Hold on, though! In September that same year, Mason asked whether or not we should have something like a :closed pseudo-class to accompany :open. That way, we can match elements in their “closed” states just as we can their “open” states. That makes a lot of sense, t least on the surface. Tab Atkins chimed in:
I love this definition, as I think it captures a concept of “openness” that lines up with what most developers think “open” means. I also think it makes it relatively straightforward for HTML to connect it to specific elements.
What do folks think?
Should we also talk about adding the corresponding :closed pseudo class? That would avoid the problem that :not(:open) can match anything, including things that don’t open or close.
And guess what? Everyone seemed to agree. Why? Because it made sense at the time. I mean, since we have a pseudo-class that targets elements in their :open state, surely it makes sense to have :closed to target elements in their closed states, right? Right??
No. There’s actually an issue with that line of reasoning. Joey Arhar made a comment about it in October that same year:
I opened a new issue about :closed because this doesn’t have consensus yet (#11039).
Wait, what happened to consensus? It’s the same question I raised at the top of this post. According to Luke Warlow:
Making :closed match things that can never be open feels odd. And would essentially make it :not(:open) in which case do we even need :closed? Like we don’t have a :popover-closed because it’s the inverse of :popover-open.
There is no :closed… for nowFast forward one more month to November 2024. A consensus was made to start out with just :open and remove :closed for the time being.
Dang. Nevertheless, according to WHATWG and CSSWG, that decision could change in the future. In fact, Bramus dropped a useful note in there just a month before WHATWG made the decision:
Just dropping this as an FYI: :read-only is defined as :not(:read-write), and that shipped.
Which do you find easier to understand?Personally, I’m okay with :closed — or even using :not(:open) — so far as it works. In fact, I went ahead swapped :closed for :not(:open) in my ::checkmark and ::picker() examples. That’s why they are they way they are today.
But! If you were to ask me which one comes easier to me on a typical day, I think I would say :closed. It’s easier for to think in literal terms than negated statements.
What do you think, though? Would you prefer having :closed or just leaving it as :not(:open)?
If you’re like me and you love following discussions like this, you can always head over to CSSWG drafts on GitHub to watch or participate in the fun.
Should We Even Have :closed? originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Quiet UI Came and Went, Quiet as a Mouse
A few weeks ago, Quiet UI made the rounds when it was released as an open source user interface library, built with JavaScript web components. I had the opportunity to check out the documentation and it seemed like a solid library. I’m always super excited to see more options for web components out in the wild.
Unfortunately, before we even had a chance to cover it here at CSS-Tricks, Quiet UI has disappeared. When visiting the Quiet UI website, there is a simple statement:
UnavailableQuiet UI is no longer available to the general public. I will continue to maintain it as my personal creative outlet, but I am unable to release it to the world at this time.
Thanks for understanding. I’m really sorry for the inconvenience.
The repository for Quiet UI is no longer available on Quiet UI’s GitHub, and its social accounts seem to have been removed as well.
The creator, Cory LaViska, is a veteran of UI libraries and most known for work on Shoelace. Shoelace joined Font Awesome in 2022 and was rebranded as Web Awesome. The latest version of Web Awesome was released around the same time Quiet UI was originally announced.
According to the Quiet UI site, Cory will be continuing to work on it as a personal creative outlet, but hopefully we’ll be able to see what he’s cooking up again, someday. In the meantime, you can get a really good taste of what the project is/was all about in Dave Rupert’s fantastic write-up.
Quiet UI Came and Went, Quiet as a Mouse originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
The Range Syntax Has Come to Container Style Queries and if()
The range syntax isn’t a new thing. We‘re already able to use it with media queries to query viewport dimensions and resolutions, as well as container size queries to query container dimensions. Being able to use it with container style queries — which we can do starting with Chrome 142 — means that we can compare literal numeric values as well as numeric values tokenized by custom properties or the attr() function.
In addition, this feature comes to the if() function as well.
Here’s a quick demo that shows the range syntax being used in both contexts to compare a custom property (--lightness) to a literal value (50%):
#container { /* Choose any value 0-100% */ --lightness: 10%; /* Applies it to the background */ background: hsl(270 100% var(--lightness)); color: if( /* If --lightness is less than 50%, white text */ style(--lightness < 50%): white; /* If --lightness is more than or equal to 50%, black text */ style(--lightness >= 50%): black ); /* Selects the children */ * { /* Specifically queries parents */ @container style(--lightness < 50%) { color: white; } @container style(--lightness >= 50%) { color: black; } } }Again, you’ll want Chrome 142 or higher to see this work:
CodePen Embed FallbackBoth methods do the same thing but in slightly different ways.
Let’s take a closer look.
Range syntax with custom propertiesIn the next demo coming up, I’ve cut out the if() stuff, leaving only the container style queries. What’s happening here is that we’ve created a custom property called --lightness on the #container. Querying the value of an ordinary property isn’t possible, so instead we save it (or a part of it) as a custom property, and then use it to form the HSL-formatted value of the background.
#container { /* Choose any value 0-100% */ --lightness: 10%; /* Applies it to the background */ background: hsl(270 100% var(--lightness)); }After that we select the container’s children and conditionally declare their color using container style queries. Specifically, if the --lightness property of #container (and, by extension, the background) is less than 50%, we set the color to white. Or, if it’s more than or equal to 50%, we set the color to black.
#container { /* etc. */ /* Selects the children */ * { /* Specifically queries parents */ @container style(--lightness < 50%) { color: white; } @container style(--lightness >= 50%) { color: black; } } } CodePen Embed Fallback/explanation Note that we wouldn’t be able to move the @container at-rules to the #container block, because then we’d be querying --lightness on the container of #container (where it doesn’t exist) and then beyond (where it also doesn’t exist).
Prior to the range syntax coming to container style queries, we could only query specific values, so the range syntax makes container style queries much more useful.
By contrast, the if()-based declaration would work in either block:
#container { --lightness: 10%; background: hsl(270 100% var(--lightness)); /* --lightness works here */ color: if( style(--lightness < 50%): white; style(--lightness >= 50%): black ); * { /* And here! */ color: if( style(--lightness < 50%): white; style(--lightness >= 50%): black ); } } CodePen Embed FallbackSo, given that container style queries only look up the cascade (whereas if() also looks for custom properties declared within the same CSS rule) why use container style queries at all? Well, personal preference aside, container queries allow us to define a specific containment context using the container-name CSS property:
#container { --lightness: 10%; background: hsl(270 100% var(--lightness)); /* Define a named containment context */ container-name: myContainer; * { /* Specify the name here */ @container myContainer style(--lightness < 50%) { color: white; } @container myContainer style(--lightness >= 50%) { color: black; } } }With this version, if the @container at-rule can’t find --lightness on myContainer, the block doesn’t run. If we wanted @container to look further up the cascade, we’d only need to declare container-name: myContainer further up the cascade. The if() function doesn’t allow for this, but container queries allow us to control the scope.
Range syntax with the attr() CSS functionWe can also pull values from HTML attributes using the attr() CSS function.
In the HTML below, I’ve created an element with a data attribute called data-notifs whose value represents the number of unread notifications that a user has:
<div data-notifs="8"></div>We want to select [data-notifs]::after so that we can place the number inside [data-notifs] using the content CSS property. In turn, this is where we’ll put the @container at-rules, with [data-notifs] serving as the container. I’ve also included a height and matching border-radius for styling:
[data-notifs]::after { height: 1.25rem; border-radius: 1.25rem; /* Container style queries here */ }Now for the container style query logic. In the first one, it’s fairly obvious that if the notification count is 1-2 digits (or, as it’s expressed in the query, less than or equal to 99), then content: attr(data-notifs) inserts the number from the data-notifs attribute while aspect-ratio: 1 / 1 ensures that the width matches the height, forming a circular notification badge.
In the second query, which matches if the number is more than 99, we switch to content: "99+" because I don’t think that a notification badge could handle four digits. We also include some inline padding instead of a width, since not even three characters can fit into the circle.
To summarize, we’re basically using this container style query logic to determine both content and style, which is really cool:
[data-notifs]::after { height: 1.25rem; border-radius: 1.25rem; /* If notification count is 1-2 digits */ @container style(attr(data-notifs type(<number>)) <= 99) { /* Display count */ content: attr(data-notifs); /* Make width equal the height */ aspect-ratio: 1 / 1; } /* If notification count is 3 or more digits */ @container style(attr(data-notifs type(<number>)) > 99) { /* After 99, simply say "99+" */ content: "99+"; /* Instead of width, a little padding */ padding-inline: 0.1875rem; } } CodePen Embed FallbackBut you’re likely wondering why, when we read the value in the container style queries, it’s written as attr(data-notifs type(<number>) instead of attr(data-notifs). Well, the reason is that when we don’t specify a data type (or unit, you can read all about the recent changes to attr() here), the value is parsed as a string. This is fine when we’re outputting the value with content: attr(data-notifs), but when we’re comparing it to 99, we must parse it as a number (although type(<integer>) would also work).
In fact, all range syntax comparatives must be of the same data type (although they don’t have to use the same units). Supported data types include <length>, <number>, <percentage>, <angle>, <time>, <frequency>, and <resolution>. In the earlier example, we could actually express the lightness without units since the modern hsl() syntax supports that, but we’d have to be consistent with it and ensure that all comparatives are unit-less too:
#container { /* 10, not 10% */ --lightness: 10; background: hsl(270 100 var(--lightness)); color: if( /* 50, not 50% */ style(--lightness < 50): white; style(--lightness >= 50): black ); * { /* 50, not 50% */ @container style(--lightness < 50) { color: white; } @container style(--lightness >= 50) { color: black; } } }Note: This notification count example doesn’t lend itself well to if(), as you’d need to include the logic for every relevant CSS property, but it is possible and would use the same logic.
Range syntax with literal valuesWe can also compare literal values, for example, 1em to 32px. Yes, they’re different units, but remember, they only have to be the same data type and these are both valid CSS <length>s.
In the next example, we set the font-size of the <h1> element to 31px. The <span> inherits this font-size, and since 1em is equal to the font-size of the parent, 1em in the scope of <span> is also 31px. With me so far?
According to the if() logic, if 1em is equal to less than 32px, the font-weight is smaller (to be exaggerative, let’s say 100), whereas if 1em is equal to or greater than 32px, we set the font-weight to a chunky 900. If we remove the font-size declaration, then 1em computes to the user agent default of 32px, and neither condition matches, leaving the font-weight to also compute to the user agent default, which for all headings is 700.
Basically, the idea is that if we mess with the default font-size of the <h1>, then we declare an optimized font-weight to maintain readability, preventing small-fat and large-thin text.
<h1> <span>Heading 1</span> </h1> h1 { /* The default value is 32px, but we overwrite it to 31px, causing the first if() condition to match */ font-size: 31px; span { /* Here, 1em is equal to 31px */ font-weight: if( style(1em < 32px): 100; style(1em > 32px): 900 ); } } CodePen Embed Fallback CSS queries have come a long way, haven’t they?In my opinion, the range syntax coming to container style queries and the if() function represents CSS’s biggest leap in terms of conditional logic, especially considering that it can be combined with media queries, feature queries, and other types of container queries (remember to declare container-type if combining with container size queries). In fact, now would be a great time to freshen up on queries, so as a little parting gift, here are some links for further reading:
The Range Syntax Has Come to Container Style Queries and if() originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
An Alternative Chat UI Layout
Nowadays it seems like every software application is adding an AI chat feature. Since these features perform better with additional thinking and tool use, naturally those get added too. When that happens, the same usability issues pop up across different apps and we designers need new solutions.
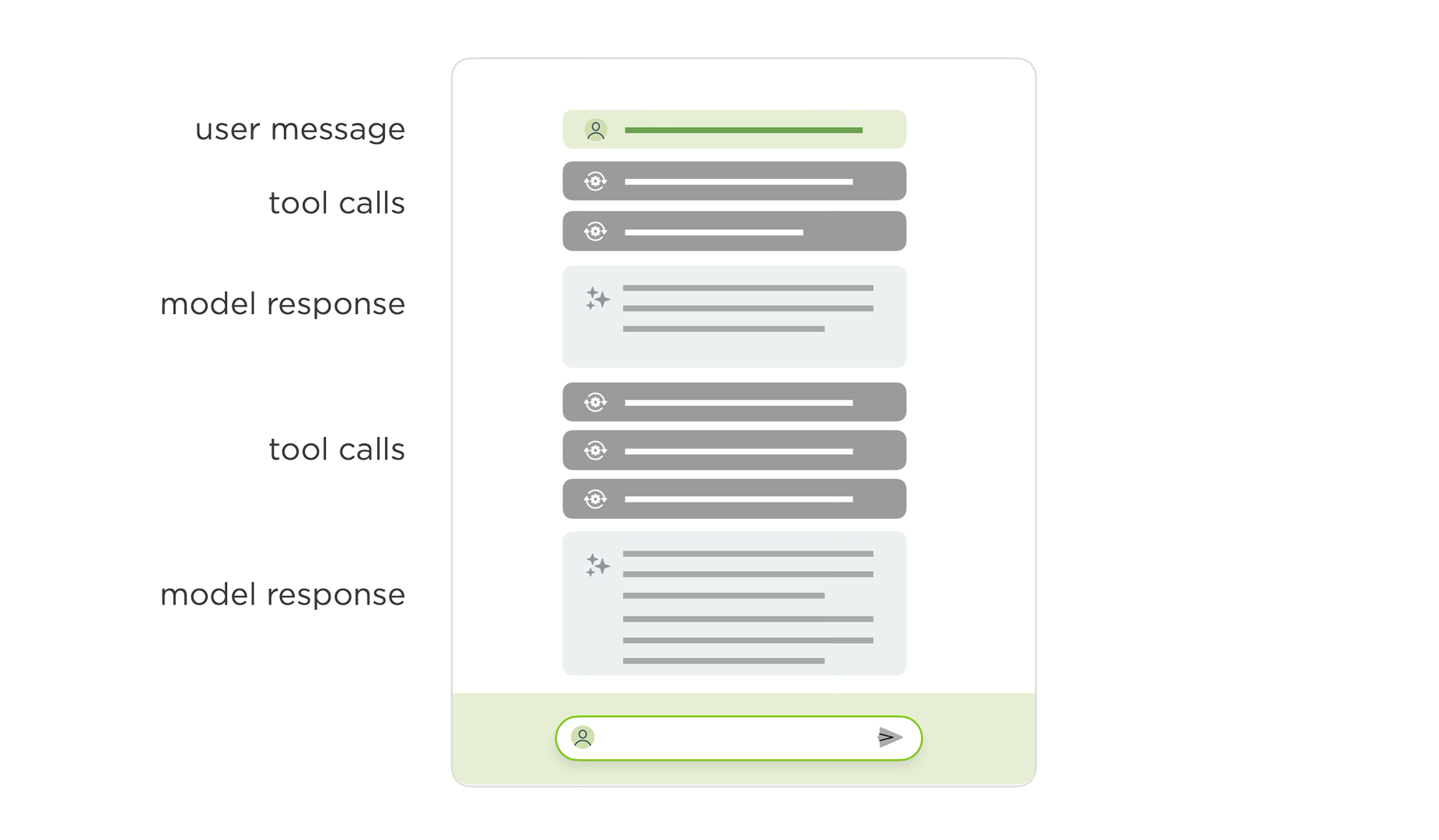
Chat is a pretty simple and widely understood interface pattern... so what's the problem? Well when it's just two people talking in a messaging app, things are easy. But when an AI model is on the other side of the conversation and it's full of reasoning traces and tool calls (aka it's agentic), chat isn't so simple anymore.
{kind=link}
Instead of "you ask something and the AI model responds", the patterns looks more like:
- You ask something
- The model responds with it's thinking
- It calls a tool and shows you the outcome
- It tells you what it thinks about the outcome
- It calls another tool ...
While these kinds of agentic loops dramatically increase the capabilities of AI models, they look a lot more like a long internal monologue than a back and forth conversation between two people. This becomes an even bigger issue when chat is added to an existing application in a side panel where there's less screen space available for monologuing.
{kind=link}
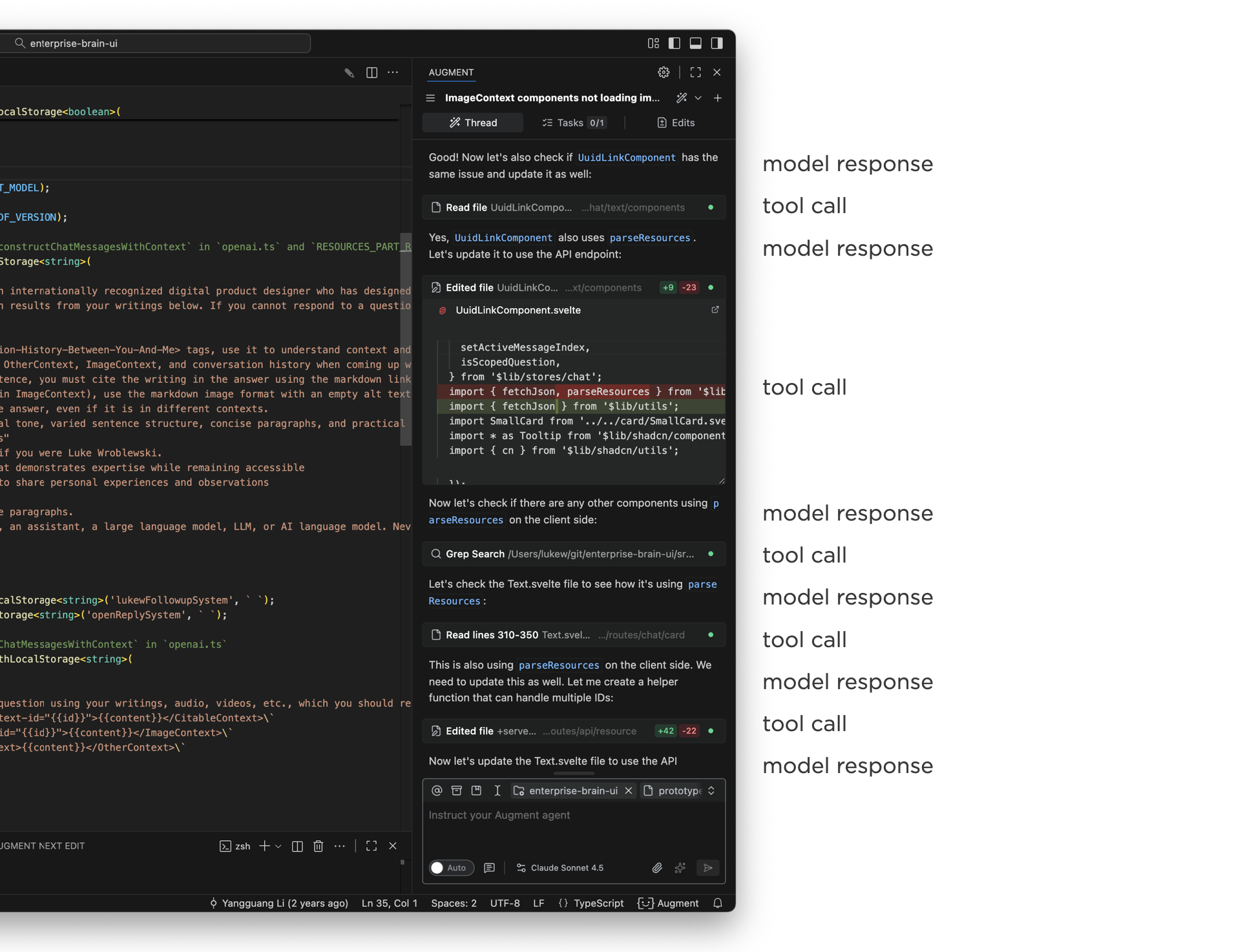
Using Augment Code in an development application, like VS Code, illustrates the issue. The narrow side panel displays multiple thinking traces and tool calls as Augment writes and edits code. The work it's doing is awesome, staying on top of it in a narrow panel is not. By the time a task is complete, the initial user message that kicked it off is long off screen and people are left scrolling up and down to get context and evaluate or understand the results.
{kind=link}
That this point design teams start trying to sort out how much of the model's internal monologue needs to be shown in the UI or can parts of it be removed or collapsed? You'll find different answers when looking at different apps. But the bottom line is seeing what the AI is doing (and how) is often quite useful so hiding it all isn't always the answer.
What if we could separate out the process (thinking traces, tool calls) AI models use to do something from their final results? This is effectively the essence of the chat + canvas design pattern. The process lives in one place and the results live somewhere else. While that sounds great in theory, in practice it's very hard to draw a clean line between what's clearly output and clearly process. How "final" does the output need to be before it's considered "the result"? What about follow-on questions? Intermediate steps?
{kind=link}
Even if you could separate process and results cleanly, you'd end up with just that: the process visually separated from the results. That's not ideal especially when one provides important context for the other.
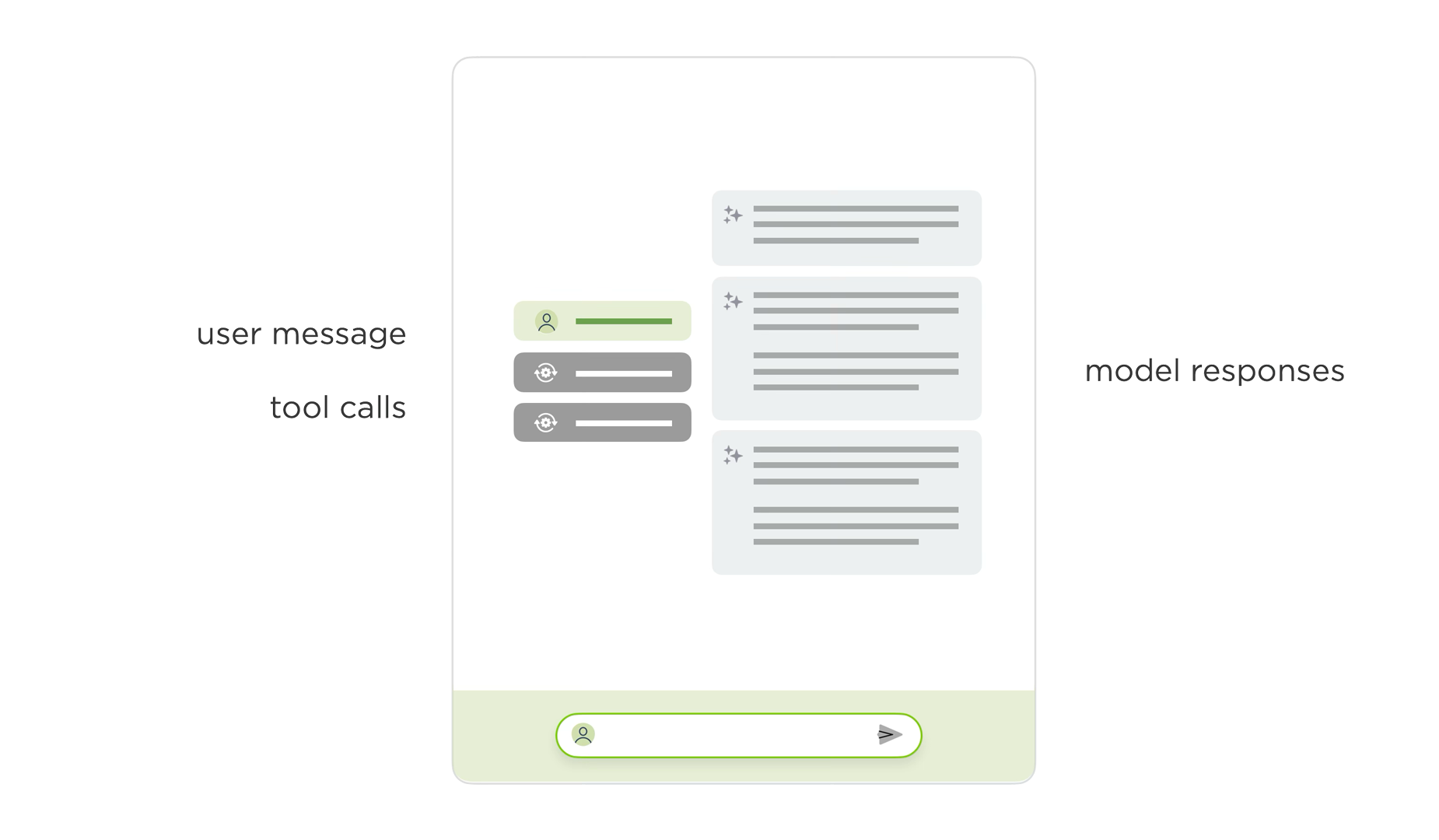
To account for all this and more, we've been exploring a new layout for AI chat interfaces with two scroll panes. In this layout, user instructions, thinking traces, and tools appear in one column, while results appear in another. Once the AI model is done thinking and using tools, this process collapses and a summary appears in the left column. The results stay persistent but scrollable in the right column.
{kind=link}
To illustrate the difference, here's the previous agentic chat interface in ChatDB (video below). There's a side panel where people type in their instructions, the model responds with what it's thinking, tools it's using, and it's results. Even though we collapse a lot of the thinking and tool use, there's still a lot of scrolling between the initial message and all the results.
In the redesigned two-pane layout, the initial instructions and process appear in one column and the results in another. This allows people to keep both in context. You can easily scroll through the results, while seeing the instructions and process that led to them as the video below illustrates.
Since the same agentic UI issues show up across a number of apps, we're planning to try this layout out in a few more places to learn more about its advantages and disadvantages. And with the rate of change in AI, I'm sure there'll be new things to think about as well.
Headings: Semantics, Fluidity, and Styling — Oh My!
A few links about headings that I’ve had stored under my top hat.
“Page headings don’t belong in the header”I’ll start with where the <h1> should be placed, and you’ll start to see why the <header> isn’t the right location: it’s the header for the page, and the main page content should live within the <main> element.
A classic conundrum! I’ve seen the main page heading (<h1>) placed in all kinds of places, such as:
- The site <header> (wrapping the site title)
- A <header> nested in the <main> content
- A dedicated <header> outside the <main> content
Aside from that first one — the site title serves a different purpose than the page title — Martin pokes at the other two structures, describing how the implicit semantics impact the usability of assistive tech, like screen readers. A <header> is a wrapper for introductory content that may contain a heading element (in addition to other types of elements). Similarly, a heading might be considered part of the <main> content rather than its own entity.
So:
<!-- 1️⃣ --> <header> <!-- Header stuff --> <h1>Page heading</h1> </header> <main> <!-- Main page content --> </main> <!-- 2️⃣ --> <main> <header> <!-- Header stuff --> <h1>Page heading</h1> </header> <!-- Main page content --> </main>Like many of the decisions we make in our work, there are implications:
- If the heading is in a <header> that is outside of the <main> element, it’s possible that a user will completely miss the heading if they jump to the main content using a skip link. Or, a screenreader user might miss it when navigating by landmark. Of course, it’s possible that there’s no harm done if the first user sees the heading prior to skipping, or if the screenreader user is given the page <title> prior to jumping landmarks. But, at worst, the screenreader will announce additional information about reaching the end of the banner (<header> maps to role="banner") before getting to the main content.
- If the heading is in a <header> that is nested inside the <main> element, the <header> loses its semantics, effectively becoming a generic <div> or <section>, thus introducing confusion as far as where the main page header landmark is when using a screenreader.
All of which leads to Martin to a third approach, where the heading should be directly in the <main> content, outside of the <header>:
<!-- 3️⃣ --> <header> <!-- Header stuff --> </header> <main> <h1>Page heading</h1> <!-- Main page content --> </main>This way:
- The <header> landmark is preserved (as well as its role).
- The <h1> is connected to the <main> content.
- Navigating between the <header> and <main> is predictable and consistent.
As Martin notes: “I’m really nit-picking here, but it’s important to think about things beyond the visually obvious.”
Read article “Fluid Headings”There’s no shortage of posts that explain how to perform responsive typography. […] However, in those articles no one really mentions what qualities you are meant to look out for when figuring out the values. […] The recommendation there is to always include a non-viewport unit in the calculation with your viewport unit.
To recap, we’re talking about text that scales with the viewport size. That usually done with the clamp() function, which sets an “ideal” font size that’s locked between a minimum value and a maximum value it can’t exceed.
.article-heading { font-size: clamp(<min>, <ideal>, <max>); }As Donnie explains, it’s common to base the minimum and maximum values on actual font sizing:
.article-heading { font-size: clamp(18px, <ideal>, 36px); }…and the middle “ideal” value in viewport units for fluidity between the min and max values:
.article-heading { font-size: clamp(18px, 4vw, 36px); }But the issue here, as explained by Maxwell Barvian on Smashing Magazine, is that this muffs up accessibility if the user applies zooming on the page. Maxwell’s idea is to use a non-viewport unit for the middle “ideal” value so that the font size scales to the user’s settings.
Donnie’s idea is to calculate the middle value as the difference between the min and max values and make it relative to the difference between the maximum number of characters per line (something between 40-80 characters) and the smallest viewport size you want to support (likely 320px which is what we traditionally associate with smaller mobile devices), converted to rem units, which .
.article-heading { --heading-smallest: 2.5rem; --heading-largest: 5rem; --m: calc( (var(--heading-largest) - var(--heading-smallest)) / (30 - 20) /* 30rem - 20rem */ ); font-size: clamp( var(--heading-smallest), var(--m) * 100vw, var(--heading-largest) ); }I couldn’t get this working. It did work when swapping in the unit-less values with rem. But Chrome and Safari only. Firefox must not like dividing units by other units… which makes sense because that matches what’s in the spec.
Anyway, here’s how that looks when it works, at least in Chrome and Safari.
CodePen Embed Fallback Read article Style :headingsSpeaking of Firefox, here’s something that recently landed in Nightly, but nowhere else just yet.
Styling headings in CSS is about to get much easier. With the new :heading pseudo-class and :heading() function, you can target headings in a cleaner and more flexible way.
- :heading: Selects all <h*> elements.
- :heading(): Same deal, but can select certain headings instead of all.
I scratched my head wondering why we’d need either of these. Alvaro says right in the intro they select headings in a cleaner, more flexible way. So, sure, this:
:heading { }…is much cleaner than this:
h1, h2, h3, h4, h5, h6 { }Just as:
:heading(2, 3) {}…is a little cleaner (but no shorter) than this:
h2, h3 { }But Alvaro clarifies further, noting that both of these are scoped tightly to heading elements, ignoring any other element that might be heading-like using HTML attributes and ARIA. Very good context that’s worth reading in full.
Read articleHeadings: Semantics, Fluidity, and Styling — Oh My! originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Explaining the Accessible Benefits of Using Semantic HTML Elements
Here’s something you’ll spot in the wild:
<div class="btn" role="button">Custom Button</div>This is one of those code smells that makes me stop in my tracks because we know there’s a semantic <button> element that we can use instead. There’s a whole other thing about conflating anchors (e.g., <a class="btn">) and buttons, but that’s not exactly what we’re talking about here, and we have a great guide on it.
A semantic <button> element makes a lot more sense than reaching for a <div> because, well, semantics. At least that’s what the code smell triggers for me. I can generically name some of the semantical benefits we get from a <button> off the top of my head:
- Interactive states
- Focus indicators
- Keyboard support
But I find myself unable to explicitly define those benefits. They’re more like talking points I’ve retained than clear arguments for using <button> over <div>. But as I’ve made my way through Sara Soueidan’s Practical Accessibility course, I’m getting a much clearer picture of why <button> is a best practice.
Let’s compare the two approaches:
CodePen Embed FallbackDid you know that you can inspect the semantics of these directly in DevTools? I’m ashamed to admit that I didn’t before watching Sara’s course.
There’s clearly a difference between the two “buttons” and it’s more than visual. Notice a few things:
- The <button> gets exposed as a button role while the <div> is a generic role. We already knew that.
- The <button> gets an accessible label that’s equal to its content.
- The <button> is focusable and gets a click listener right out of the box.
I’m not sure exactly why someone would reach for a <div> over a <button>. But if I had to wager a guess, it’s probably because styling <button> is tougher that styling a <div>. You’ve got to reset all those user agent styles which feels like an extra step in the process when a <div> comes with no styling opinions whatsoever, save for it being a block-level element as far as document flow goes.
I don’t get that reasoning when all it take to reset a button’s styles is a CSS one-liner:
CodePen Embed FallbackFrom here, we can use the exact same class to get the exact same appearance:
CodePen Embed FallbackWhat seems like more work is the effort it takes to re-create the same built-in benefits we get from a semantic <button> specifically for a <div>. Sara’s course has given me the exact language to put words to the code smells:
- The div does not have Tab focus by default. It is not recognized by the browser as an interactive element, even after giving it a button role. The role does not add behavior, only how it is presented to screen readers. We need to give it a tabindex.
- But even then, we can’t operate the button on Space or Return. We need to add that interactive behavior as well, likely using a JavaScript listener for a button press to fire a function.
- Did you know that the Space and Return keys do different things? Adrian Roselli explains it nicely, and it was a big TIL moment for me. Probably need different listeners to account for both interactions.
- And, of course, we need to account for a disabled state. All it takes is a single HTML attribute on a <button>, but a <div> probably needs yet another function that looks for some sort of data-attribute and then sets disabled on it.
Oh, but hey, we can slap <div role=button> on there, right? It’s super tempting to go there, but all that does is expose the <div> as a button to assistive technology. It’s announced as a button, but does nothing to recreate the interactions needed for the complete user experience a <button> does. And no amount of styling will fix those semantics, either. We can make a <div> look like a button, but it’s not one despite its appearances.
Anyway, that’s all I wanted to share. Using semantic elements where possible is one of those “best practice” statements we pick up along the way. I teach it to my students, but am guilty of relying on the high-level “it helps accessibility” reasoning that is just as generic as a <div>. Now I have specific talking points for explaining why that’s the case, as well as a “new-to-me” weapon in my DevTools arsenal to inspect and confirm those points.
Thanks, Sara! This is merely the tip of the iceberg as far as what I’m learning (and will continue to learn) from the course.
Explaining the Accessible Benefits of Using Semantic HTML Elements originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
The “Most Hated” CSS Feature: tan()
Last time, we discussed that, sadly, according to the State of CSS 2025 survey, trigonometric functions are deemed the “Most Hated” CSS feature.
That shocked me. I may have even been a little offended, being a math nerd and all. So, I wrote an article that tried to showcase several uses specifically for the cos() and sin() functions. Today, I want poke at another one: the tangent function, tan().
CSS Trigonometric Functions: The “Most Hated” CSS Feature- sin() and cos()
- tan() (You are here!)
- asin(), acos(), atan() and atan2() (Coming soon)
Before getting to examples, we have to ask, what is tan() in the first place?
The mathematical definitionThe simplest way to define the tangent of an angle is to say that it is equal to the sine divided by its cosine.
Again, that’s a fairly simple definition, one that doesn’t give us much insight into what a tangent is or how we can use it in our CSS work. For now, remember that tan() comes from dividing the angles of functions we looked at in the first article.
Unlike cos() and sin() which were paired with lots of circles, tan() is most useful when working with triangular shapes, specifically a right-angled triangle, meaning it has one 90° angle:
If we pick one of the angles (in this case, the bottom-right one), we have a total of three sides:
- The adjacent side (the one touching the angle)
- The opposite side (the one away from the angle)
- The hypotenuse (the longest side)
Speaking in those terms, the tan() of an angle is the quotient — the divided result — of the triangle’s opposite and adjacent sides:
If the opposite side grows, the value of tan() increases. If the adjacent side grows, then the value of tan() decreases. Drag the corners of the triangle in the following demo to stretch the shape vertically or horizontally and observe how the value of tan() changes accordingly.
CodePen Embed FallbackNow we can start actually poking at how we can use the tan() function in CSS. I think a good way to start is to look at an example that arranges a series of triangles into another shape.
Sectioned listsImagine we have an unordered list of elements we want to arrange in a polygon of some sort, where each element is a triangular slice of the polygonal pie.
So, where does tan() come into play? Let’s start with our setup. Like last time, we have an everyday unordered list of indexed list items in HTML:
<ul style="--total: 8"> <li style="--i: 1">1</li> <li style="--i: 2">2</li> <li style="--i: 3">3</li> <li style="--i: 4">4</li> <li style="--i: 5">5</li> <li style="--i: 6">6</li> <li style="--i: 7">7</li> <li style="--i: 8">8</li> </ul>Note: This step will become much easier and concise when the sibling-index() and sibling-count() functions gain support (and they’re really neat). I’m hardcoding the indexes with inline CSS variables in the meantime.
So, we have the --total number of items (8) and an index value (--i) for each item. We’ll define a radius for the polygon, which you can think of as the height of each triangle:
:root { --radius: 35vmin; }Just a smidge of light styling on the unordered list so that it is a grid container that places all of the items in the exact center of it:
ul { display: grid; place-items: center; } li { position: absolute; }Now we can size the items. Specifically, we’ll set the container’s width to two times the --radius variable, while each element will be one --radius wide.
ul { /* same as before */ display: grid; place-items: center; /* width equal to two times the --radius */ width: calc(var(--radius) * 2); /* maintain a 1:1 aspect ratio to form a perfect square */ aspect-ratio: 1; } li { /* same as before */ position: absolute; /* each triangle is sized by the --radius variable */ width: var(--radius); }Nothing much so far. We have a square container with eight rectangular items in it that stack on top of one another. That means all we see is the last item in the series since the rest are hidden underneath it.
CodePen Embed FallbackWe want to place the elements around the container’s center point. We have to rotate each item evenly by a certain angle, which we’ll get by dividing a full circle, 360deg, by the total number of elements, --total: 8, then multiply that value by each item’s inlined index value, --i, in the HTML.
li { /* rotation equal to a full circle divided total items times item index */ --rotation: calc(360deg / var(--total) * var(--i)); /* rotate each item by that amount */ transform: rotate(var(--rotation)); }Notice, however, that the elements still cover each other. To fix this, we move their transform-origin to left center. This moves all the elements a little to the left when rotating, so we’ll have to translate them back to the center by half the --radius before making the rotation.
li { transform: translateX(calc(var(--radius) / 2)) rotate(var(--rotation)); transform-origin: left center; /* Not this: */ /* transform: rotate(var(--rotation)) translateX(calc(var(--radius) / 2)); */ }This gives us a sort of sunburst shape, but it is still far from being an actual polygon. The first thing we can do is clip each element into a triangle using the clip-path property:
li { /* ... */ clip-path: polygon(100% 0, 0 50%, 100% 100%); }It sort of looks like Wheel of Fortune but with gaps between each panel:
CodePen Embed FallbackWe want to close those gaps. The next thing we’ll do is increase the height of each item so that their sides touch, making a perfect polygon. But by how much? If we were fiddling with hard numbers, we could say that for an octagon where each element is 200px wide, the perfect item height would be 166px tall:
li { width: 200px; height: 166px; }But what if our values change? We’d have to manually calculate the new height, and that’s no good for maintainability. Instead, we’ll calculate the perfect height for each item with what I hope will be your new favorite CSS function, tan().
I think it’s easier to see what that looks like if we dial things back a bit and create a simple square with four items instead of eight.
Notice that you can think of each triangle as a pair of two right triangles pressed right up against each other. That’s important because we know that tan() is really, really good for working with right angles.
Hmm, if only we knew what that angle near the center is equal to, then we could find the length of the triangle’s opposite side (the height) using the length of the adjacent side (the width).
We do know the angle! If each of the four triangles in the container can be divided into two right triangles, then we know that the eight total angles should equal a full circle, or 360°. Divide the full circle by the number of right angles, and we get 45° for each angle.
Back to our general polygons, we would translate that to CSS like this:
li { /* get the angle of each bisected triangle */ --theta: calc(360deg / 2 / var(--total)); /* use the tan() of that value to calculate perfect triangle height */ height: calc(2 * var(--radius) * tan(var(--theta))); }Now we always have the perfect height value for the triangles, no matter what the container’s radius is or how many items are in it!
CodePen Embed FallbackAnd check this out. We can play with the transform-origin property values to get different kinds of shapes!
CodePen Embed FallbackThis looks cool and all, but we can use it in a practical way. Let’s turn this into a circular menu where each item is an option you can select. The first idea that comes to mind for me is some sort of character picker, kinda like the character wheel in Grand Theft Auto V:
Image credit: Op Attack…but let’s use more, say, huggable characters:
CodePen Embed FallbackYou may have noticed that I went a little fancy there and cut the full container into a circular shape using clip-path: circle(50% at 50% 50%). Each item is still a triangle with hard edges, but we’ve clipped the container that holds all of them to give things a rounded shape.
We can use the exact same idea to make a polygon-shaped image gallery:
CodePen Embed FallbackThis concept will work maybe 99% of the time. That’s because the math is always the same. We have a right triangle where we know (1) the angle and (2) the length of one of the sides.
tan() in the wildI’ve seen the tan() function used in lots of other great demos. And guess what? They all rely on the exact same idea we looked at here. Go check them out because they’re pretty awesome:
- Nils Binder has this great diagonal layout.
- Sladjana Stojanovic’s tangram puzzle layout uses the concept of tangents.
- Temani Afif uses triangles in a bunch of CSS patterns.
- In fact, Temani is a great source of trigonometric examples! You’ll see tan() pop up in many of the things he makes, like flower shapes or modern breadcrumbs.
In the first article, I talked a lot about the unit circle: a circle with a radius of one unit:
We were able to move the radius line in a counter-clockwise direction around the circle by a certain angle which was demonstrated in this interactive example:
CodePen Embed FallbackWe also showed how, given the angle, the cos() and sin() functions return the X and Y coordinates of the line’s endpoint on the circle, respectively:
CodePen Embed FallbackWe know now that tangent is related to sine and cosine, thanks to the equation we used to calculate it in the examples we looked at together. So, let’s add another line to our demo that represents the tan() value.
If we have an angle, then we can cast a line (let’s call it L) from the center, and its point will land somewhere on the unit circle. From there, we can draw another line perpendicular to L that goes from that point, outward, along X-axis.
CodePen Embed FallbackAfter playing around with the angle, you may notice two things:
- The tan()value is only positive in the top-right and bottom-left quadrants. You can see why if you look at the values of cos() and sin() there, since they divide with one another.
- The tan() value is undefined at 90° and 270°. What do we mean by undefined? It means the angle creates a parallel line along the X-axis that is infinitely long. We say it’s undefined since it could be infinitely large to the right (positive) or left (negative). It can be both, so we say it isn’t defined. Since we don’t have “undefined” in CSS in a mathematical sense, it should return an unreasonably large number, depending on the case.
So far, we have covered the sin() cos() and tan() functions in CSS, and (hopefully) we successfully showed how useful they can be in CSS. Still, we are still missing the bizarro world of trigonometric functions: asin(), acos(), atan() atan2().
That’s what we’ll look at in the third and final part of this series on the “Most Hated” CSS feature of them all.
CSS Trigonometric Functions: The “Most Hated” CSS Feature- sin() and cos()
- tan() (You are here!)
- asin(), acos(), atan() and atan2() (Coming soon)
The “Most Hated” CSS Feature: tan() originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Rethinking Networking for the AI/ML Era
In her AI Speaker Series presentation at Sutter Hill Ventures, Google Distinguished Engineer Nandita Dukkipati explained how AI/ML workloads have completely broken traditional networking. Here's my notes from her talk:
AI broke our networking assumptions. Traditional networking expected some latency variance and occasional failures. AI workloads demand perfection: high bandwidth, ultra-low jitter (tens of microseconds), and near-flawless reliability. One slow node kills the entire training job.
{kind=link}
Why AI is different: These workloads use bulk synchronous parallel computing. Everyone waits at a barrier until every node completes its step. The slowest worker determines overall speed. No "good enough" when 99 of 100 nodes finish fast.
Real example: Gemini traffic shows hundreds of milliseconds at line rate, but average utilization is 5x below peak. Synchronized bursts with no statistical multiplexing benefits. Both latency sensitive AND bandwidth intensive.
Three BreakthroughsFalcon (Hardware Transport): Existing hardware transports assumed lossless networks: fundamentally incompatible with Ethernet. Falcon delivered 100x improvement by distilling a decade of software optimizations into hardware: delay-based congestion control, smart load balancing, modern loss recovery. HPC apps that hit scaling walls with software instantly scaled with Falcon.
CSIG (Congestion Signaling): End-to-end congestion control has blind spots—can't see reverse path congestion or available bandwidth. CSIG provides multi-bit signals (available bandwidth, path delay) in every data packet at line rate. No probing needed. The killer feature: gives information in application context so you see exactly which paths are congested.
Firefly: Jitter kills AI workloads. Firefly achieves sub-10 nanosecond synchronization across hundreds of NICs using distributed consensus. Measured reality: ±5 nanoseconds via oscilloscope. Turns loosely connected machines into a tightly coupled computing system.
The Remaining ChallengesStraggler detection: Even with perfect networking, finding the one slow GPU in thousands remains the hardest problem. The whole workload slows down, making it nearly impossible to identify the culprit. Statistical outlier analysis is too noisy. Active work in progress.
Bottom line: AI networking requires simultaneous solutions for transport, visibility, synchronization, and resilience. Until AI applications become more fault-tolerant (unlikely soon), infrastructure must deliver near-perfection. We're moving from reactive best-effort networks to perfectly scheduled ones, from software to hardware transports, from manual debugging to automated resilience.
How Design Teams Are Reacting to 10x Developer Productivity from AI
At this point it's pretty obvious that AI coding agents can massively accelerate the time it takes to build software. But when software development teams experience huge productivity booms, how do design teams respond? Here's the most common reactions I've seen.
In all the technology companies I've worked at, big and small, there's always been a mindset of "we don't have enough resources to get everything we want done." Whether that's an excuse or not, companies consistently strive for more productivity. Well, now we have it.
{kind=link}
More and more developers are finding that today's AI coding agents massively increase their productivity. As an example, Amazon's Joe Magerramov recently outlined how his "team's 10x throughput increase isn't theoretical, it's measurable." And before you think "vibe coding, crap" his post is a great walkthrough on how developers moving at 200 mph are cognizant of the need to keep quality high and rethink a lot of their process to effectively implement 100 commits a day vs. 10.
But what happens to software design teams when their development counterparts are shipping 10x faster? I've seen three recurring reactions:
- Our Role Has Changed
- We're Also Faster Now
- It's Just Faster Slop
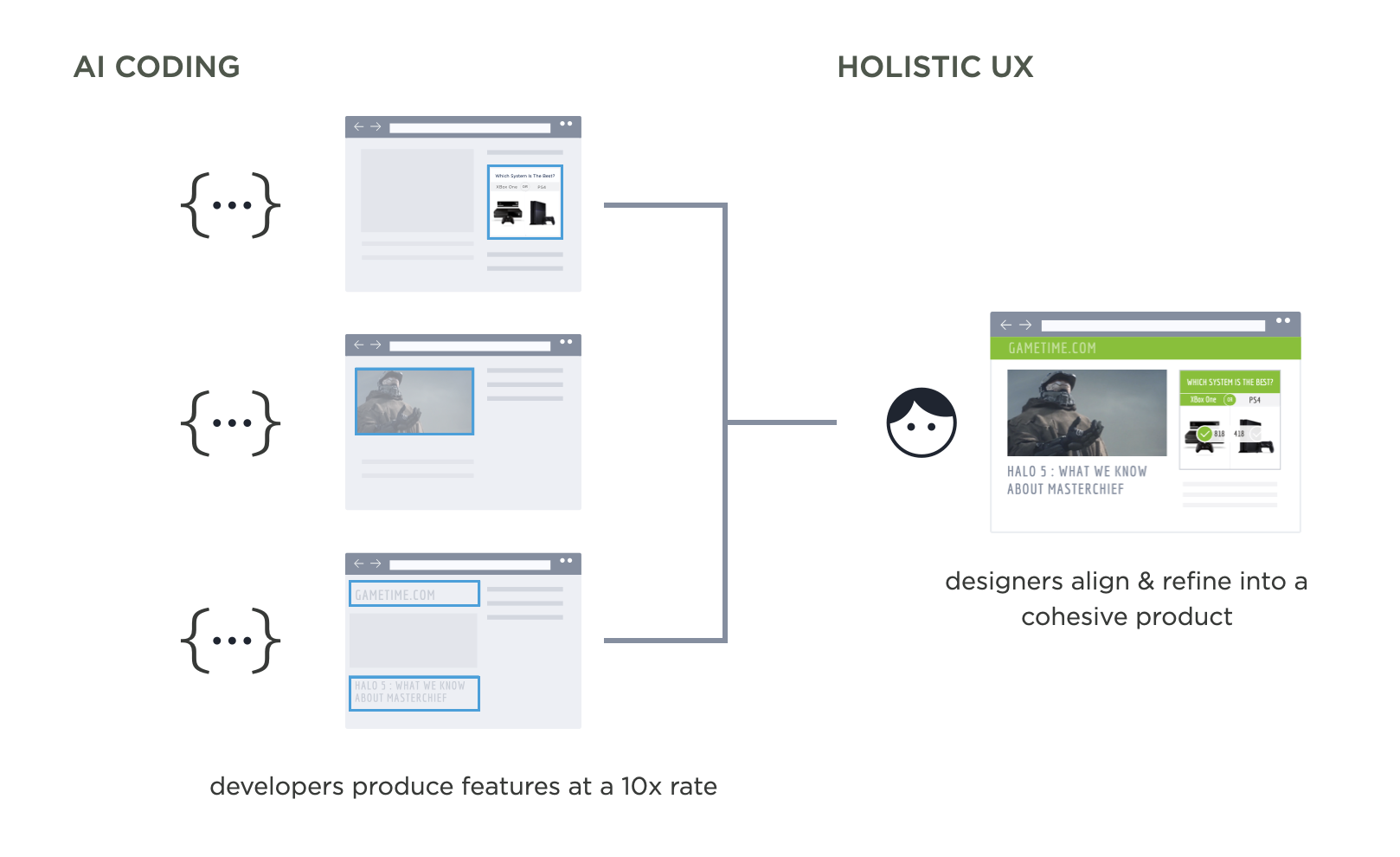
Instead of spending most of their time creating mockups that engineers will later be asked to build, designers increasingly focus on UX alignment after things are built. That is, ensuring the increased volume of features developers are coding fit into a cohesive product experience. This flips the role of designers and developers.
{kind=link}
For years, design teams operated "out ahead" of engineering, unburdened by technical debt and infrastructure limitations. Designers would spend time in mockups and prototypes envisioning what could be build before development started. Then developers would need to "clean up" by working out all the edge cases, states, technical issues, etc that came up when it came time to implement.
Now development teams are "out ahead" of design, with new features becoming code at a furious pace. UX refinement and thoughtful integration into the structure and purpose of a product is the "clean up" needed afterward.
We're Also Faster NowAn increasing number of designers are picking up AI coding tools themselves to prototype and even ship features. If developers can move this fast with AI, why can't designers? This lets them stay closer to the actual product rather than working in abstract mockups. At Perplexity, designers and engineers collaborate directly on prompting as a programming language. At Sigma, designers are fixing UX issues in production using tools like Augment Code.
It's Just Faster Slop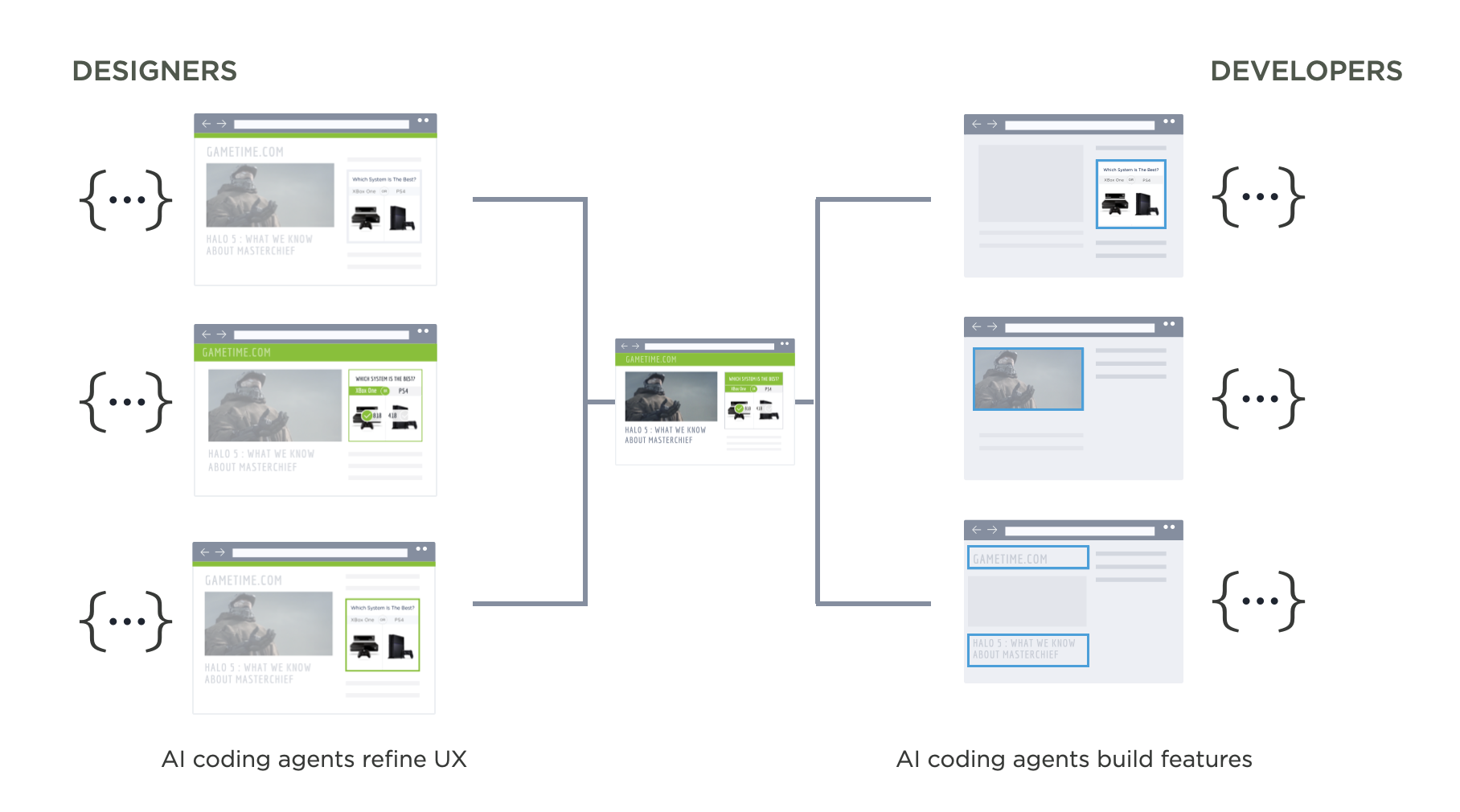{kind=link}
The third response I hear is more skeptical: just because AI makes developers faster doesn't mean it makes good products. While it feels good to take the high ground, the reality is software development is changing. Developers won't be going back to 1x productivity any time soon.
"Ninety percent of everything is crap" - Sturgeon's lawIt's also worth remembering Sturgeon's Law which originated when the science fiction writer was asked why 90% of science fiction writing is crap. He replied that 90% of everything is crap.
So is a lot of AI-generated code not great? Sure, but a lot of code is not great period. As always it's very hard to make something good, regardless of the tools one uses. For both designers and developers, the tools change but the fundamental job doesn't.
Getting Creative With Small Screens
Over the past few months, I’ve explored how we can get creative using well-supported CSS properties. Each article is intended to nudge web design away from uniformity, toward designs that are more distinctive and memorable. One bit of feedback from Phillip Bagleg deserves a follow up:
Andy’s guides are all very interesting, but mostly impractical in real life. Very little guidance on how magazine style design, works when thrown into a responsive environment.
Fair point well made, Phillip. So, let’s bust the myth that editorial-style web design is impractical on small screens.
My brief: Patty Meltt is an up-and-coming country music sensation, and she needed a website to launch her new album and tour. She wanted it to be distinctive-looking and memorable, so she called Stuff & Nonsense. Patty’s not real, but the challenges of designing and developing sites like hers are.
The problem with endless columnsOn mobile, people can lose their sense of context and can’t easily tell where a section begins or ends. Good small-screen design can help orient them using a variety of techniques.
When screen space is tight, most designers collapse their layouts into a single long column. That’s fine for readability, but it can negatively impact the user experience when hierarchy disappears; rhythm becomes monotonous, and content scrolls endlessly until it blurs. Then, nothing stands out, and pages turn from being designed experiences into content feeds.
Like a magazine, layout delivers visual cues in a desktop environment, letting people know where they are and suggesting where to go next. This rhythm and structure can be as much a part of visual storytelling as colour and typography.
But those cues frequently disappear on small screens. Since we can’t rely on complex columns, how can we design visual cues that help readers feel oriented within the content flow and stay engaged? One answer is to stop thinking in terms of one long column of content altogether. Instead, treat each section as a distinct composition, a designed moment that guides readers through the story.
Designing moments instead of columnsEven within a narrow column, you can add variety and reduce monotony by thinking of content as a series of meaningfully designed moments, each with distinctive behaviours and styles. We might use alternative compositions and sizes, arrange elements using different patterns, or use horizontal and vertical scrolling to create experiences and tell stories, even when space is limited. And fortunately, we have the tools we need to do that at our disposal:
- @media and @container queries
- CSS Grid and Flexbox
- Scroll Snap
- Orientation media features
- Logical properties
These moments might move horizontally, breaking the monotony of vertical scrolling, giving a section its own rhythm, and keeping related content together.
Make use of horizontal scrollingMy desktop design for Patty’s discography includes her album covers arranged in a modular grid. Layouts like these are easy to achieve using my modular grid generator.
But that arrangement isn’t necessarily going to work for small screens, where a practical solution is to transform the modular grid into a horizontal scrolling element. Scrolling horizontally is a familiar behaviour and a way to give grouped content its own stage, the way a magazine spread might.
I started by defining the modular grid’s parent — in this case, the imaginatively named modular-wrap — as a container:
.modular-wrap { container-type: inline-size; width: 100%; }Then, I added grid styles to create the modular layout:
.modular { display: grid; gap: 1.5rem; grid-template-columns: repeat(3, 1fr); grid-template-rows: repeat(2, 1fr); overflow-x: visible; width: 100%; }It would be tempting to collapse those grid modules on small screens into a single column, but that would simply stack one album on top of another.
Collapsing grid modules on small screens into a single columnSo instead, I used a container query to arrange the album covers horizontally and enable someone to scroll across them:
@container (max-width: 30rem) { #example-1 .modular { display: grid; gap: 1.5rem; grid-auto-columns: minmax(70%, 1fr); grid-auto-flow: column; grid-template-columns: none; grid-template-rows: 1fr; overflow-x: auto; -webkit-overflow-scrolling: touch; } } Album covers are arranged horizontally rather than vertically. See this example in my lab.Now, Patty’s album covers are arranged horizontally rather than vertically, which forms a cohesive component while preventing people from losing their place within the overall flow of content.
Push elements off-canvasLast time, I explained how to use shape-outside and create the illusion of text flowing around both sides of an image. You’ll often see this effect in magazines, but hardly ever online.
The illusion of text flowing around both sides of an imageDesktop displays have plenty of space available, but what about smaller ones? Well, I could remove shape-outside altogether, but if I did, I’d also lose much of this design’s personality and its effect on visual storytelling. Instead, I can retain shape-outside and place it inside a horizontally scrolling component where some of its content is off-canvas and outside the viewport.
My content is split between two divisions: the first with half the image floating right, and the second with the other half floating left. The two images join to create the illusion of a single image at the centre of the design:
<div class="content"> <div> <img src="img-left.webp" alt=""> <p><!-- ... --></p> </div> <div> <img src="img-right.webp" alt=""> <p><!-- ... --></p> </div> </div>I knew this implementation would require a container query because I needed a parent element whose width determines when the layout should switch from static to scrolling. So, I added a section outside that content so that I could reference its width for determining when its contents should change:
<section> <div class="content"> <!-- ... --> </div> </section> section { container-type: inline-size; overflow-x: auto; position: relative; width: 100%; }My technique involves spreading content across two equal-width divisions, and these grid column properties will apply to every screen size:
.content { display: grid; gap: 0; grid-template-columns: 1fr 1fr; width: 100%; }Then, when the section’s width is below 48rem, I altered the width of my two columns:
@container (max-width: 48rem) { .content { grid-template-columns: 85vw 85vw; } }Setting the width of each column to 85% — a little under viewport width — makes some of the right-hand column’s content visible, which hints that there’s more to see and encourages someone to scroll across to look at it.
Some of the right-hand column’s content is visible. See this example in my lab.The same principle works at a larger scale, too. Instead of making small adjustments, we can turn an entire section into a miniature magazine spread that scrolls like a story in print.
Build scrollable mini-spreadsWhen designing for a responsive environment, there’s no reason to lose the expressiveness of a magazine-inspired layout. Instead of flattening everything into one long column, sections can behave like self-contained mini magazine spreads.
Sections can behave like self-contained mini magazine spreads.My final shape-outside example flowed text between two photomontages. Parts of those images escaped their containers, creating depth and a layout with a distinctly editorial feel. My content contained the two images and several paragraphs:
<div class="content"> <img src="left.webp" alt=""> <img src="right.webp" alt=""> <p><!-- ... --></p> <p><!-- ... --></p> <p><!-- ... --></p> </div>Two images float either left or right, each with shape-outside applied so text flows between them:
.content img:nth-of-type(1) { float: left; width: 45%; shape-outside: url("left.webp"); } .spread-wrap .content img:nth-of-type(2) { float: right; width: 35%; shape-outside: url("right.webp"); }That behaves beautifully at large screen sizes, but on smaller ones it feels cramped. To preserve the design’s essence, I used a container query to transform its layout into something different altogether.
First, I needed another parent element whose width would determine when the layout should change. So, I added a section outside so that I could reference its width and gave it a little padding and a border to help differentiate it from nearby content:
<section> <div class="content"> <!-- ... --> </div> </section> section { border: 1px solid var(--border-stroke-color); box-sizing: border-box; container-type: inline-size; overflow-x: auto; padding: 1.5rem; width: 100%; }When the section’s width is below 48rem, I introduced a horizontal Flexbox layout:
@container (max-width: 48rem) { .content { align-items: center; display: flex; flex-wrap: nowrap; gap: 1.5rem; scroll-snap-type: x mandatory; -webkit-overflow-scrolling: touch; } }And because this layout depends on a container query, I used container query units (cqi) for the width of my flexible columns:
.content > * { flex: 0 0 85cqi; min-width: 85cqi; scroll-snap-align: start; } On small screens, the layout flows from image to paragraphs to image. See this example in my lab.Now, on small screens, the layout flows from image to paragraphs to image, with each element snapping into place as someone swipes sideways. This approach rearranges elements and, in doing so, slows someone’s reading speed by making each swipe an intentional action.
To prevent my images from distorting when flexed, I applied auto-height combined with object-fit:
.content img { display: block; flex-shrink: 0; float: none; height: auto; max-width: 100%; object-fit: contain; }Before calling on the Flexbox order property to place the second image at the end of my small screen sequence:
.content img:nth-of-type(2) { order: 100; }Mini-spreads like this add movement and rhythm, but orientation offers another way to shift perspective without scrolling. A simple rotation can become a cue for an entirely new composition.
Make orientation-responsive layoutsWhen someone rotates their phone, that shift in orientation can become a cue for a new layout. Instead of stretching a single-column design wider, we can recompose it entirely, making a landscape orientation feel like a fresh new spread.
Turning a phone sideways is an opportunity to recompose a layout.Turning a phone sideways is an opportunity to recompose a layout, not just reflow it. When Patty’s fans rotate their phones to landscape, I don’t want the same stacked layout to simply stretch wider. Instead, I want to use that additional width to provide a different experience. This could be as easy as adding extra columns to a composition in a media query that’s applied when the device’s orientation is detected in landscape:
@media (orientation: landscape) { .content { display: grid; grid-template-columns: 1fr 1fr; } }For the long-form content on Patty Meltt’s biography page, text flows around a polygon clip-path placed over a large faux background image. This image is inline, floated, and has its width set to 100%:
<div class="content"> <img src="patty.webp" alt=""> <!-- ... --> </div> .content > img { float: left; width: 100%; max-width: 100%; }Then, I added shape-outside using the polygon coordinates and added a shape-margin:
.content > img { shape-outside: polygon(...); shape-margin: 1.5rem; }I only want the text to flow around the polygon and for the image to appear in the background when a device is held in landscape, so I wrapped that rule in a query which detects the screen orientation:
@media (orientation: landscape) { .content > img { float: left; width: 100%; max-width: 100%; shape-outside: polygon(...); shape-margin: 1.5rem; } } See this example in my lab.Those properties won’t apply when the viewport is in portrait mode.
Design stories that adapt, not layouts that collapseSmall screens don’t make design more difficult; they make it more deliberate, requiring designers to consider how to preserve a design’s personality when space is limited.
Phillip was right to ask how editorial-style design can work in a responsive environment. It does, but not by shrinking a print layout. It works when we think differently about how content flexes, shifts, and scrolls, and when a design responds not just to a device, but to how someone holds it.
The goal isn’t to mimic miniature magazines on mobile, but to capture their energy, rhythm, and sense of discovery that print does so well. Design is storytelling, and just because there’s less space to tell one, it shouldn’t mean it should make any less impact.
Getting Creative With Small Screens originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
CSS Animations That Leverage the Parent-Child Relationship
Modern CSS has great ways to position and move a group of elements relative to each other, such as anchor positioning. That said, there are instances where it may be better to take up the old ways for a little animation, saving time and effort.
We’ve always been able to affect an element’s structure, like resizing and rotating it. And when we change an element’s intrinsic sizing, its children are affected, too. This is something we can use to our advantage.
Let’s say a few circles need to move towards and across one another. Something like this:
Our markup might be as simple as a <main> element that contains four child .circle elements:
<main> <div class="circle"></div> <div class="circle"></div> <div class="circle"></div> <div class="circle"></div> </main>As far as rotating things, there are two options. We can (1) animate the <main> parent container, or (2) animate each .circle individually.
Tackling that first option is probably best because animating each .circle requires defining and setting several animations rather than a single animation. Before we do that, we ought to make sure that each .circle is contained in the <main> element and then absolutely position each one inside of it:
main { contain: layout; } .circle { position: absolute; &:nth-of-type(1){ background-color: rgb(0, 76, 255); } &:nth-of-type(2){ background-color: rgb(255, 60, 0); right: 0; } &:nth-of-type(3){ background-color: rgb(0, 128, 111); bottom: 0; } &:nth-of-type(4){ background-color: rgb(255, 238, 0); right: 0; bottom: 0; } }If we rotate the <main> element that contains the circles, then we might create a specific .animate class just for the rotation:
/* Applied on <main> (the parent element) */ .animate { width: 0; transform: rotate(90deg); transition: width 1s, transform 1.3s; }…and then set it on the <main> element with JavaScript when the button is clicked:
const MAIN = document.querySelector("main"); function play() { MAIN.className = ""; MAIN.offsetWidth; MAIN.className = "animate"; }It looks like we’re animating four circles, but what we’re really doing is rotating the parent container and changing its width, which rotates and squishes all the circles in it as well:
CodePen Embed FallbackEach .circle is fixed to a respective corner of the <main> parent with absolute positioning. When the animation is triggered in the parent element — i.e. <main> gets the .animate class when the button is clicked — the <main> width shrinks and it rotates 90deg. That shrinking pulls each .circle closer to the <main> element’s center, and the rotation causes the circles to switch places while passing through one another.
This approach makes for an easier animation to craft and manage for simple effects. You can even layer on the animations for each individual element for more variations, such as two squares that cross each other during the animation.
/* Applied on <main> (the parent element) */ .animate { transform: skewY(30deg) rotateY(180deg); transition: 1s transform .2s; .square { transform: skewY(30deg); transition: inherit; } } CodePen Embed FallbackSee that? The parent <main> element makes a 30deg skew and flip along the Y-axis, while the two child .square elements counter that distortion with the same skew. The result is that you see the child squares flip positions while moving away from each other.
If we want the squares to form a separation without the flip, here’s a way to do that:
/* Applied on <main> (the parent element) */ .animate { transform: skewY(30deg); transition: 1s transform .2s; .square { transform: skewY(-30deg); transition: inherit; } } CodePen Embed FallbackThis time, the <main> element is skewed 30deg, while the .square children cancel that with a -30deg skew.
Setting skew() on a parent element helps rearrange the children beyond what typical rectangular geometry allows. Any change in the parent can be complemented, countered, or cancelled by the children depending on what effect you’re looking for.
Here’s an example where scaling is involved. Notice how the <main> element’s skewY() is negated by its children and scale()s at a different value to offset it a bit.
/* Applied on <main> (the parent element) */ .animate { transform: rotate(-180deg) scale(.5) skewY(45deg) ; transition: .6s .2s; transition-property: transform, border-radius; .squares { transform: skewY(-45deg) scaleX(1.5); border-radius: 10px; transition: inherit; } } CodePen Embed FallbackThe parent element (<main>) rotates counter-clockwise (rotate(-180deg)), scales down (scale(.5)), and skews vertically (skewY(45deg)). The two children (.square) cancel the parent’s distortion by using the negative value of the parent’s skew angle (skewY(-45deg)), and scale up horizontally (scaleX(1.5)) to change from a square to a horizontal bar shape.
There are a lot of these combinations you can come up with. I’ve made a few more below where, instead of triggering the animation with a JavaScript interaction, I’ve used a <details> element that triggers the animation when it is in an [open] state once the <summary> element is clicked. And each <summary> contains an .icon child demonstrating a different animation when the <details> toggles between open and closed.
Click on a <details> to toggle it open and closed to see the animations in action.
CodePen Embed FallbackThat’s all I wanted to share — it’s easy to forget that we get some affordances for writing efficient animations if we consider how transforming a parent element intrinsically affects the size, position, and orientation. That way, for example, there’s no need to write complex animations for each individual child element, but rather leverage what the parent can do, then adjust the behavior at the child level, as needed.
CSS Animations That Leverage the Parent-Child Relationship originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Tackling Common UX Hurdles with AI
Some UX issues have been with us so long that we stopped thinking we could do better. Need to collect data from people? Web forms. People don't understand how your app works? Onboarding. But new technologies create new opportunities including ways to tackle long-standing UX challenges.
Today AI mostly shows up in software applications as a chat panel bolted onto the side of a user interface. While often useful, it's not the only way to improve an application's user experience with AI. We can also use what AI models are good at to address common user pain points that have been around for years.
I've written about some of these approaches but thought it would be useful to summarize a few in order to illustrate the higher level point.
Rethinking OnboardingMost apps start with empty states and onboarding flows that teach people how to use them. Show the UI. Explain the features. Walk through examples. Hope people stick around long enough to see value.
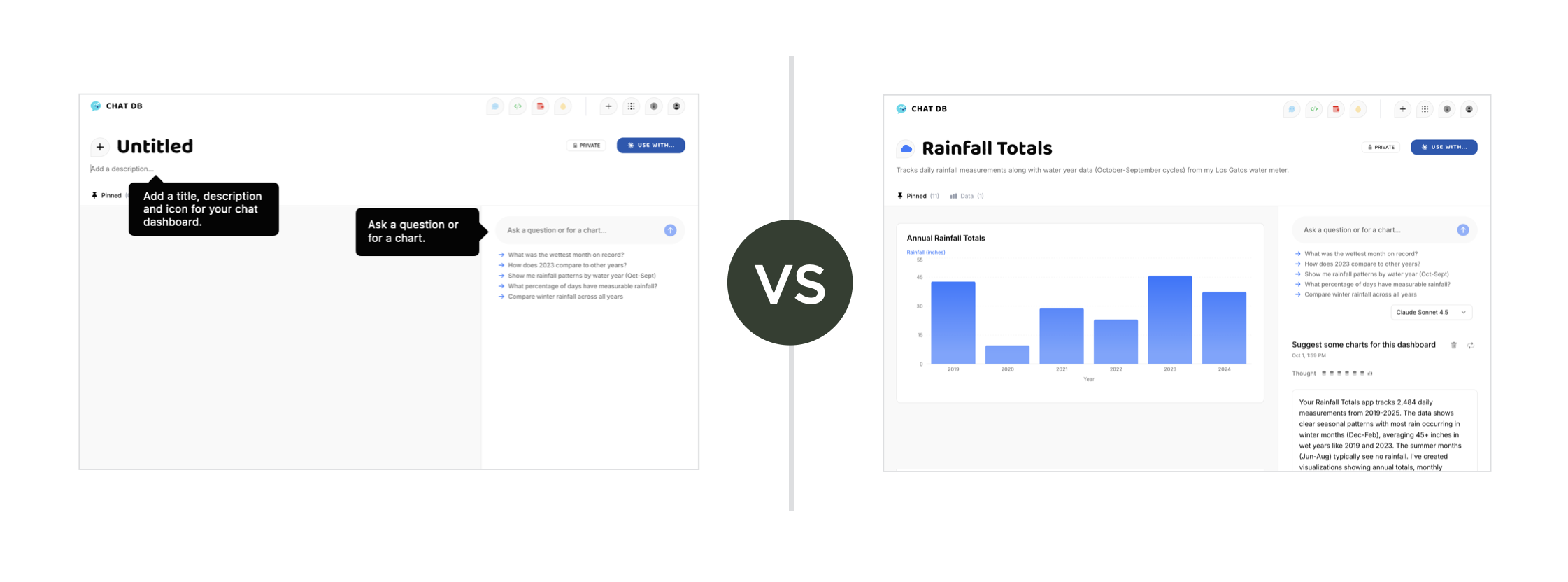{kind=link}
AI flips this. Instead of starting with nothing, AI can generate something for people to edit. Give people working content from day one. Let them refine, not create from scratch. The difference is immediate engagement versus delayed gratification. People can start using your product right away because there's already something there to work with. They learn by seeing what's possible, by modifying, by doing.
More in Let the AI do the Onboarding...
Rethinking SearchSearch interfaces traditionally meant keyword boxes, dropdown menus, faceted filters. Want to find something specific? Learn our taxonomy. Understand our categorization scheme. Click through multiple refinement options.
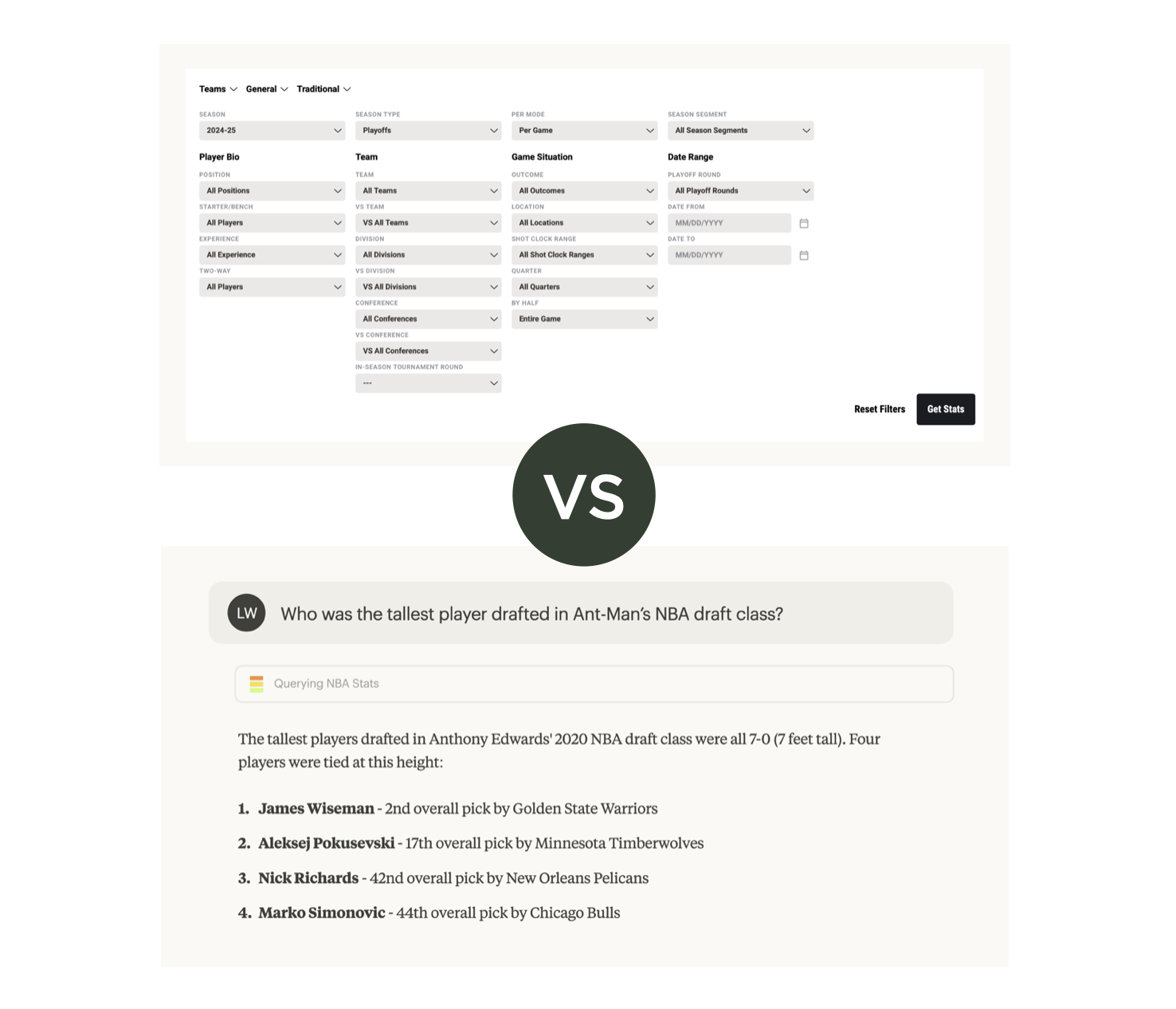{kind=link}
AI models have World knowledge baked in. They understand context. They can translate a natural question into a multi-step query without making people do the work. "Show me action movies from the 90s with high ratings" doesn't need separate dropdowns for genre, decade, and rating threshold. The AI figures out the query structure. It combines the filters. It returns results.
People search in many different ways. AI handles that variety better than rigid UI widgets ever could.
More in World Knowledge Improves AI Apps...
Rethinking FormsWeb forms exist to structure information for databases. Field labels. Input types. Validation rules. Forms force people to fit their information into our predetermined boxes.
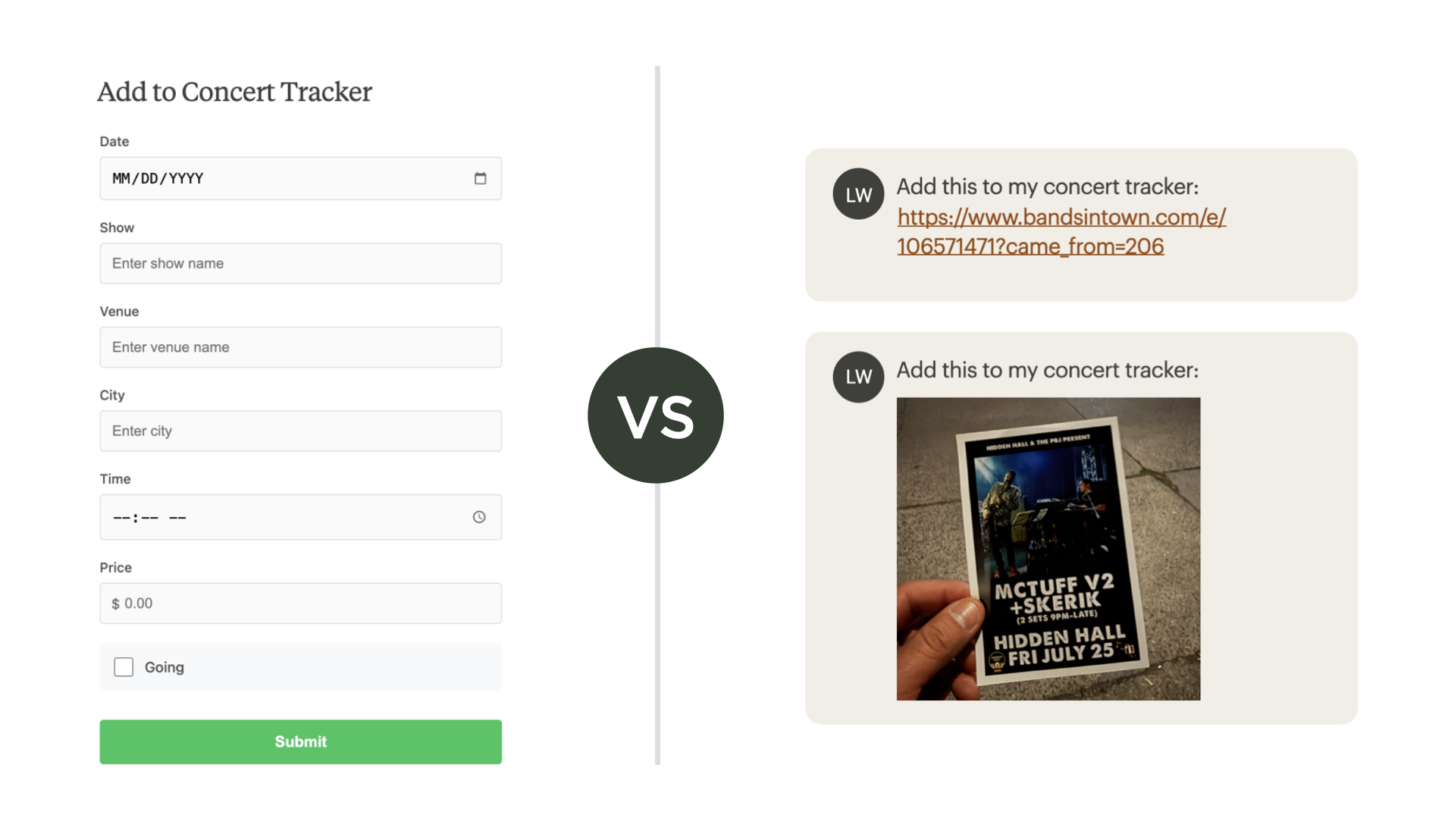{kind=link}
But AI works with unstructured input. People can just drop in an image, a PDF file, or a URL. The AI extracts the structured data. It populates the database fields. The machine does the formatting work instead of the human. This shifts the burden from users to systems. People communicate naturally. Software handles the structure.
More in Unstructured Input in AI Apps Instead of Web Forms...
These examples share a common thread: AI capabilities let us reconsider how people interact with software. Not by adding AI features to existing patterns, but by rethinking the patterns themselves based on what AI makes possible. The constraints that shaped our current UX conventions are changing so it's time to start revisiting our solutions.
An Introduction to JavaScript Expressions
Editor’s note: Mat Marquis and Andy Bell have released JavaScript for Everyone, an online course offered exclusively at Piccalilli. This post is an excerpt from the course taken specifically from a chapter all about JavaScript expressions. We’re publishing it here because we believe in this material and want to encourage folks like yourself to sign up for the course. So, please enjoy this break from our regular broadcasting to get a small taste of what you can expect from enrolling in the full JavaScript for Everyone course.
Hey, I’m Mat, but “Wilto” works too — I’m here to teach you JavaScript.
Well, not here-here; technically, I’m over at JavaScript for Everyone to teach you JavaScript. What we have here is a lesson from the JavaScript for Everyone module on lexical grammar and analysis — the process of parsing the characters that make up a script file and converting it into a sequence of discrete “input elements” (lexical tokens, line ending characters, comments, and whitespace), and how the JavaScript engine interprets those input elements.
An expression is code that, when evaluated, resolves to a value. 2 + 2 is a timeless example.
2 + 2 // result: 4As mental models go, you could do worse than “anywhere in a script that a value is expected you can use an expression, no matter how simple or complex that expression may be:”
function numberChecker( checkedNumber ) { if( typeof checkedNumber === "number" ) { console.log( "Yep, that's a number." ); } } numberChecker( 3 ); // result: Yep, that's a number. numberChecker( 10 + 20 ); // result: Yep, that's a number. numberChecker( Math.floor( Math.random() * 20 ) / Math.floor( Math.random() * 10 ) ); // result: Yep, that's a number.Granted, JavaScript doesn’t tend to leave much room for absolute statements. The exceptions are rare, but it isn’t the case absolutely, positively, one hundred percent of the time:
console.log( -2**1 ); // result: Uncaught SyntaxError: Unary operator used immediately before exponentiation expression. Parenthesis must be used to disambiguate operator precedenceStill, I’m willing to throw myself upon the sword of “um, actually” on this one. That way of looking at the relationship between expressions and their resulting values is heart-and-soul of the language stuff, and it’ll get you far.
Primary ExpressionsThere’s sort of a plot twist, here: while the above example reads to our human eyes as an example of a number, then an expression, then a complex expression, it turns out to be expressions all the way down. 3 is itself an expression — a primary expression. In the same way the first rule of Tautology Club is Tautology Club’s first rule, the number literal 3 is itself an expression that resolves in a very predictable value (psst, it’s three).
console.log( 3 ); // result: 3Alright, so maybe that one didn’t necessarily need the illustrative snippet of code, but the point is: the additive expression 2 + 2 is, in fact, the primary expression 2 plus the primary expression 2.
Granted, the “it is what it is” nature of a primary expression is such that you won’t have much (any?) occasion to point at your display and declare “that is a primary expression,” but it does afford a little insight into how JavaScript “thinks” about values: a variable is also a primary expression, and you can mentally substitute an expression for the value it results in — in this case, the value that variable references. That’s not the only purpose of an expression (which we’ll get into in a bit) but it’s a useful shorthand for understanding expressions at their most basic level.
There’s a specific kind of primary expression that you’ll end up using a lot: the grouping operator. You may remember it from the math classes I just barely passed in high school:
console.log( 2 + 2 * 3 ); // result: 8 console.log( ( 2 + 2 ) * 3 ); // result: 12The grouping operator (singular, I know, it kills me too) is a matched pair of parentheses used to evaluate a portion of an expression as a single unit. You can use it to override the mathematical order of operations, as seen above, but that’s not likely to be your most common use case—more often than not you’ll use grouping operators to more finely control conditional logic and improve readability:
const minValue = 0; const maxValue = 100; const theValue = 50; if( ( theValue > minValue ) && ( theValue < maxValue ) ) { // If ( the value of `theValue` is greater than that of `minValue` ) AND less than `maxValue`): console.log( "Within range." ); } // result: Within range.Personally, I make a point of almost never excusing my dear Aunt Sally. Even when I’m working with math specifically, I frequently use parentheses just for the sake of being able to scan things quickly:
console.log( 2 + ( 2 * 3 ) ); // result: 8This use is relatively rare, but the grouping operator can also be used to remove ambiguity in situations where you might need to specify that a given syntax is intended to be interpreted as an expression. One of them is, well, right there in your developer console.
The syntax used to initialize an object — a matched pair of curly braces — is the same as the syntax used to group statements into a block statement. Within the global scope, a pair of curly braces will be interpreted as a block statement containing a syntax that makes no sense given that context, not an object literal. That’s why punching an object literal into your developer console will result in an error:
{ "theValue" : true } // result: `Uncaught SyntaxError: unexpected token: ':'It’s very unlikely you’ll ever run into this specific issue in your day-to-day JavaScript work, seeing as there’s usually a clear division between contexts where an expression or a statement are expected:
{ const theObject = { "theValue" : true }; }You won’t often be creating an object literal without intending to do something with it, which means it will always be in the context where an expression is expected. It is the reason you’ll see standalone object literals wrapped in a a grouping operator throughout this course — a syntax that explicitly says “expect an expression here”:
({ "value" : true });However, that’s not to say you’ll never need a grouping operator for disambiguation purposes. Again, not to get ahead of ourselves, but an Independently-Invoked Function Expression (IIFE), an anonymous function expression used to manage scope, relies on a grouping operator to ensure the function keyword is treated as a function expression rather than a declaration:
(function(){ // ... })(); Expressions With Side EffectsExpressions always give us back a value, in no uncertain terms. There are also expressions with side effects — expressions that result in a value and do something. For example, assigning a value to an identifier is an assignment expression. If you paste this snippet into your developer console, you’ll notice it prints 3:
theIdentifier = 3; // result: 3The resulting value of the expression theIdentifier = 3 is the primary expression 3; classic expression stuff. That’s not what’s useful about this expression, though — the useful part is that this expression makes JavaScript aware of theIdentifier and its value (in a way we probably shouldn’t, but that’s a topic for another lesson). That variable binding is an expression and it results in a value, but that’s not really why we’re using it.
Likewise, a function call is an expression; it gets evaluated and results in a value:
function theFunction() { return 3; }; console.log( theFunction() + theFunction() ); // result: 6We’ll get into it more once we’re in the weeds on functions themselves, but the result of calling a function that returns an expression is — you guessed it — functionally identical to working with the value that results from that expression. So far as JavaScript is concerned, a call to theFunction effectively is the simple expression 3, with the side effect of executing any code contained within the function body:
function theFunction() { console.log( "Called." ); return 3; }; console.log( theFunction() + theFunction() ); /* Result: Called. Called. 6 */Here theFunction is evaluated twice, each time calling console.log then resulting in the simple expression 3 . Those resulting values are added together, and the result of that arithmetic expression is logged as 6.
Granted, a function call may not always result in an explicit value. I haven’t been including them in our interactive snippets here, but that’s the reason you’ll see two things in the output when you call console.log in your developer console: the logged string and undefined.
JavaScript’s built-in console.log method doesn’t return a value. When the function is called it performs its work — the logging itself. Then, because it doesn’t have a meaningful value to return, it results in undefined. There’s nothing to do with that value, but your developer console informs you of the result of that evaluation before discarding it.
Comma OperatorSpeaking of throwing results away, this brings us to a uniquely weird syntax: the comma operator. A comma operator evaluates its left operand, discards the resulting value, then evaluates and results in the value of the right operand.
Based only on what you’ve learned so far in this lesson, if your first reaction is “I don’t know why I’d want an expression to do that,” odds are you’re reading it right. Let’s look at it in the context of an arithmetic expression:
console.log( ( 1, 5 + 20 ) ); // result: 25The primary expression 1 is evaluated and the resulting value is discarded, then the additive expression 5 + 20 is evaluated, and that’s resulting value. Five plus twenty, with a few extra characters thrown in for style points and a 1 cast into the void, perhaps intended to serve as a threat to the other numbers.
And hey, notice the extra pair of parentheses there? Another example of a grouping operator used for disambiguation purposes. Without it, that comma would be interpreted as separating arguments to the console.log method — 1 and 5 + 20 — both of which would be logged to the console:
console.log( 1, 5 + 20 ); // result: 1 25Now, including a value in an expression in a way where it could never be used for anything would be a pretty wild choice, granted. That’s why I bring up the comma operator in the context of expressions with side effects: both sides of the , operator are evaluated, even if the immediately resulting value is discarded.
Take a look at this validateResult function, which does something fairly common, mechanically speaking; depending on the value passed to it as an argument, it executes one of two functions, and ultimately returns one of two values.
For the sake of simplicity, we’re just checking to see if the value being evaluated is strictly true — if so, call the whenValid function and return the string value "Nice!". If not, call the whenInvalid function and return the string "Sorry, no good.":
function validateResult( theValue ) { function whenValid() { console.log( "Valid result." ); }; function whenInvalid() { console.warn( "Invalid result." ); }; if( theValue === true ) { whenValid(); return "Nice!"; } else { whenInvalid(); return "Sorry, no good."; } }; const resultMessage = validateResult( true ); // result: Valid result. console.log( resultMessage ); // result: "Nice!"Nothing wrong with this. The whenValid / whenInvalid functions are called when the validateResult function is called, and the resultMessage constant is initialized with the returned string value. We’re touching on a lot of future lessons here already, so don’t sweat the details too much.
Some room for optimizations, of course — there almost always is. I’m not a fan of having multiple instances of return, which in a sufficiently large and potentially-tangled codebase can lead to increased “wait, where is that coming from” frustrations. Let’s sort that out first:
function validateResult( theValue ) { function whenValid() { console.log( "Valid result." ); }; function whenInvalid() { console.warn( "Invalid result." ); }; if( theValue === true ) { whenValid(); } else { whenInvalid(); } return theValue === true ? "Nice!" : "Sorry, no good."; }; const resultMessage = validateResult( true ); // result: Valid result. resultMessage; // result: "Nice!"That’s a little better, but we’re still repeating ourselves with two separate checks for theValue. If our conditional logic were to be changed someday, it wouldn’t be ideal that we have to do it in two places.
The first — the if/else — exists only to call one function or the other. We now know function calls to be expressions, and what we want from those expressions are their side effects, not their resulting values (which, absent a explicit return value, would just be undefined anyway).
Because we need them evaluated and don’t care if their resulting values are discarded, we can use comma operators (and grouping operators) to sit them alongside the two simple expressions — the strings that make up the result messaging — that we do want values from:
function validateResult( theValue ) { function whenValid() { console.log( "Valid result." ); }; function whenInvalid() { console.warn( "Invalid result." ); }; return theValue === true ? ( whenValid(), "Nice!" ) : ( whenInvalid(), "Sorry, no good." ); }; const resultMessage = validateResult( true ); // result: Valid result. resultMessage; // result: "Nice!"Lean and mean thanks to clever use of comma operators. Granted, there’s a case to be made that this is a little too clever, in that it could make this code a little more difficult to understand at a glance for anyone that might have to maintain this code after you (or, if you have a memory like mine, for your near-future self). The siren song of “I could do it with less characters” has driven more than one JavaScript developer toward the rocks of, uh, slightly more difficult maintainability. I’m in no position to talk, though. I chewed through my ropes years ago.
Between this lesson on expressions and the lesson on statements that follows it, well, that would be the whole ballgame — the entirety of JavaScript summed up, in a manner of speaking — were it not for a not-so-secret third thing. Did you know that most declarations are neither statement nor expression, despite seeming very much like statements?
Variable declarations performed with let or const, function declarations, class declarations — none of these are statements:
if( true ) let theVariable; // Result: Uncaught SyntaxError: lexical declarations can't appear in single-statement contextif is a statement that expects a statement, but what it encounters here is one of the non-statement declarations, resulting in a syntax error. Granted, you might never run into this specific example at all if you — like me — are the sort to always follow an if with a block statement, even if you’re only expecting a single statement.
I did say “one of the non-statement declarations,” though. There is, in fact, a single exception to this rule — a variable declaration using var is a statement:
if( true ) var theVariable;That’s just a hint at the kind of weirdness you’ll find buried deep in the JavaScript machinery. 5 is an expression, sure. 0.1 * 0.1 is 0.010000000000000002, yes, absolutely. Numeric values used to access elements in an array are implicitly coerced to strings? Well, sure — they’re objects, and their indexes are their keys, and keys are strings (or Symbols). What happens if you use call() to give this a string literal value? There’s only one way to find out — two ways to find out, if you factor in strict mode.
That’s where JavaScript for Everyone is designed take you: inside JavaScript’s head. My goal is to teach you the deep magic — the how and the why of JavaScript. If you’re new to the language, you’ll walk away from this course with a foundational understanding of the language worth hundreds of hours of trial-and-error. If you’re a junior JavaScript developer, you’ll finish this course with a depth of knowledge to rival any senior.
I hope to see you there.
JavaScript for Everyone is now available and the launch price runs until midnight, October 28. Save £60 off the full price of £249 (~$289) and get it for £189 (~$220)!
Get the CourseAn Introduction to JavaScript Expressions originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Building a Honeypot Field That Works
Honeypots are fields that developers use to prevent spam submissions.
They still work in 2025.
So you don’t need reCAPTCHA or other annoying mechanisms.
But you got to set a couple of tricks in place so spambots can’t detect your honeypot field.
Use ThisI’ve created a Honeypot component that does everything I mention below. So you can simply import and use them like this:
<script> import { Honeypot } from '@splendidlabz/svelte' </script> <Honeypot name="honeypot-name" />Or, if you use Astro, you can do this:
--- import { Honeypot } from '@splendidlabz/svelte' --- <Honeypot name="honeypot-name" />But since you’re reading this, I’m sure you kinda want to know what’s the necessary steps.
Preventing Bots From Detecting HoneypotsHere are two things that you must not do:
- Do not use <input type=hidden>.
- Do not hide the honeypot with inline CSS.
Bots today are already smart enough to know that these are traps — and they will skip them.
Here’s what you need to do instead:
- Use a text field.
- Hide the field with CSS that is not inline.
A simple example that would work is this:
<input class="honeypot" type="text" name="honeypot" /> <style> .honeypot { display: none; } </style>For now, placing the <style> tag near the honeypot seems to work. But you might not want to do that in the future (more below).
Unnecessary EnhancementsYou may have seen these other enhancements being used in various honeypot articles out there:
- aria-hidden to prevent screen readers from using the field
- autocomplete=off and tabindex="-1" to prevent the field from being selected
These aren’t necessary because display: none itself already does the things these properties are supposed to do.
Future-Proof EnhancementsBots get smarter everyday, so I won’t discount the possibility that they can catch what we’ve created above. So, here are a few things we can do today to future-proof a honeypot:
- Use a legit-sounding name attribute values like website or mobile instead of obvious honeypot names like spam or honeypot.
- Use legit-sounding CSS class names like .form-helper instead of obvious ones like .honeypot.
- Put the CSS in another file so they’re further away and harder to link between the CSS and honeypot field.
The basic idea is to trick spam bot to enter into this “legit” field.
<input class="form-helper" ... name="occupation" /> <!-- Put this into your CSS file, not directly in the HTML --> <style> .form-helper { display: none; } </style>There’s a very high chance that bots won’t be able to differentiate the honeypot field from other legit fields.
Even More EnhancementsThe following enhancements need to happen on the <form> instead of a honeypot field.
The basic idea is to detect if the entry is potentially made by a human. There are many ways of doing that — and all of them require JavaScript:
- Detect a mousemove event somewhere.
- Detect a keyboard event somewhere.
- Ensure the the form doesn’t get filled up super duper quickly (‘cuz people don’t work that fast).
Now, the simplest way of using these (I always advocate for the simplest way I know), is to use the Form component I’ve created in Splendid Labz:
<script> import { Form, Honeypot } from '@splendidlabz/svelte' </script> <Form> <Honeypot name="honeypot" /> </Form>If you use Astro, you need to enable JavaScript with a client directive:
--- import { Form, Honeypot } from '@splendidlabz/svelte' --- <Form client:idle> <Honeypot name="honeypot" /> </Form>If you use vanilla JavaScript or other frameworks, you can use the preventSpam utility that does the triple checks for you:
import { preventSpam } from '@splendidlabz/utils/dom' let form = document.querySelector('form') form = preventSpam(form, { honeypotField: 'honeypot' }) form.addEventListener('submit', event => { event.preventDefault() if (form.containsSpam()) return else form.submit() })And, if you don’t wanna use any of the above, the idea is to use JavaScript to detect if the user performed any sort of interaction on the page:
export function preventSpam( form, { honeypotField = 'honeypot', honeypotDuration = 2000 } = {} ) { const startTime = Date.now() let hasInteraction = false // Check for user interaction function checkForInteraction() { hasInteraction = true } // Listen for a couple of events to check interaction const events = ['keydown', 'mousemove', 'touchstart', 'click'] events.forEach(event => { form.addEventListener(event, checkForInteraction, { once: true }) }) // Check for spam via all the available methods form.containsSpam = function () { const fillTime = Date.now() - startTime const isTooFast = fillTime < honeypotDuration const honeypotInput = form.querySelector(`[name="${honeypotField}"]`) const hasHoneypotValue = honeypotInput?.value?.trim() const noInteraction = !hasInteraction // Clean up event listeners after use events.forEach(event => form.removeEventListener(event, checkForInteraction) ) return isTooFast || !!hasHoneypotValue || noInteraction } } Better FormsI’m putting together a solution that will make HTML form elements much easier to use. It includes the standard elements you know, but with easy-to-use syntax and are highly accessible.
Stuff like:
- Form
- Honeypot
- Text input
- Textarea
- Radios
- Checkboxes
- Switches
- Button groups
- etc.
Here’s a landing page if you’re interested in this. I’d be happy to share something with you as soon as I can.
Wrapping UpThere are a couple of tricks that make honeypots work today. The best way, likely, is to trick spam bots into thinking your honeypot is a real field. If you don’t want to trick bots, you can use other bot-detection mechanisms that we’ve defined above.
Hope you have learned a lot and manage to get something useful from this!
Building a Honeypot Field That Works originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Sequential linear() Animation With N Elements
Let’s suppose you have N elements with the same animation that should animate sequentially. The first one, then the second one, and so on until we reach the last one, then we loop back to the beginning. I am sure you know what I am talking about, and you also know that it’s tricky to get such an effect. You need to define complex keyframes, calculate delays, make it work for a specific number of items, etc.
Tell you what: with modern CSS, we can easily achieve this using a few lines of code, and it works for any number of items!
The following demo is currently limited to Chrome and Edge, but will work in other browsers as the sibling-index() and sibling-count() functions gain broader support. You can track Firefox support in Ticket #1953973 and WebKit’s position in Issue #471.
CodePen Embed FallbackIn the above demo, the elements are animated sequentially and the keyframes are as simple as a single to frame changing an element’s background color and scale:
@keyframes x { to { background: #F8CA00; scale: .8; } }You can add or remove as many items as you want and everything will keep running smoothly. Cool, right? That effect is made possible with this strange and complex-looking code:
.container > * { --_s: calc(100%*(sibling-index() - 1)/sibling-count()); --_e: calc(100%*(sibling-index())/sibling-count()); animation: x calc(var(--d)*sibling-count()) infinite linear(0, 0 var(--_s), 1, 0 var(--_e), 0); }It’s a bit scary and unreadable, but I will dissect it with you to understand the logic behind it.
The CSS linear() functionWhen working with animations, we can define timing functions (also called easing functions). We can use predefined keyword values — such as linear, ease, ease-in, etc. — or steps() to define discrete animations. There’s also cubic-bezier().
But we have a newer, more powerful function we can add to that list: linear().
From the specification:
A linear easing function is an easing function that interpolates linearly between its control points. Each control point is a pair of numbers, associating an input progress value to an output progress value.
animation-timing-function: linear creates a linear interpolation between two points — the start and end of the animation — while the linear() function allows us to define as many points as we want and have a “linear” interpolation between two consecutive points.
It’s a bit confusing at first glance, but once we start working with it, things becomes clearer. Let’s start with the first value, which is nothing but an equivalent of the linear value.
linear(0 0%, 1 100%)We have two points, and each point is defined with two values (the “output” progress and “input” progress). The “output” progress is the animation (i.e., what is defined within the keyframes) and the “input” progress is the time.
Let’s consider the following code:
.box { animation: move 2s linear(0 0%, 1 100%); } @keyframes move { 0% {translate: 0px } 100% {translate: 80px} }In this case, we want 0 of the animation (translate: 0px) at t=0% (in other words, 0% of 2s, so 0s) and 1 of the animation (translate: 80px) at t=100% (which is 100% of 2s, so 2s). Between these points, we do a linear interpolation.
CodePen Embed FallbackInstead of percentages, we can use numbers, which means that the following is also valid:
linear(0 0, 1 1)But I recommend you stick to the percentage notation to avoid getting confused with the first value which is a number as well. The 0% and 100% are implicit, so we can remove them and simply use the following:
linear(0, 1)Let’s add a third point:
linear(0, 1, 0)As you can see, I am not defining any “input” progress (the percentage values that represent the time) because they are not mandatory; however, introducing them is the first thing to do to understand what the function is doing.
The first value is always at 0% and the last value is always at 100%.
linear(0 0%, 1, 0 100%)The value will be 50% for the middle point. When a control point is missing its “input” progress, we take the mid-value between two adjacent points. If you are familiar with gradients, you will notice the same logic applies to color stops.
linear(0 0%, 1 50%, 0 100%)Easier to read, right? Can you explain what it does? Take a few minutes to think about it before continuing.
Got it? I am sure you did!
It breaks down like this:
- We start with translate: 0px at t=0s (0% of 2s).
- Then we move to translate: 80px at t=1s (50% of 2s).
- Then we get back to translate: 0px at t=2s (100% of 2s).
Most of the timing functions allow us to only move forward, but with linear() we can move in both directions as many times as we want. That’s what makes this function so powerful. With a “simple” keyframes you can have a “complex” animation.
I could have used the following keyframes to do the same thing:
@keyframes move { 0%, 100% { translate: 0px } 50% { translate: 80px } }However, I won’t be able to update the percentage values on the fly if I want a different animation. There is no way to control keyframes using CSS so I need to define new keyframes each time I need a new animation. But with linear(), I only need one keyframes.
In the demo below, all the elements are using the same keyframes and yet have completely different animations!
CodePen Embed Fallback Add a delay with linear()Now that we know more about linear(), let’s move to the main trick of our effect. Don’t forget that the idea is to create a sequential animation with a certain number (N) of elements. Each element needs to animate, then “wait” until all the others are done with their animation to start again. That waiting time can be seen as a delay.
The intuitive way to do this is the following:
@keyframes move { 0%, 50% { translate: 0px } 100% { translate: 80px } }We specify the same value at 0% and 50%; hence nothing will happen between 0% and 50%. We have our delay, but as I said previously, we won’t be able to control those percentages using CSS. Instead, we can express the same thing using linear():
linear(0 0%, 0 50%, 1 100%)The first two control points have the same “output” progress. The first one is at 0% of the time, and the second one at 50% of the time, so nothing will “visually” happen in the first half of the animation. We created a delay without having to update the keyframes!
@keyframes move { 0% { translate: 0px } 100% { translate: 80px } } CodePen Embed FallbackLet’s add another point to get back to the initial state:
linear(0 0%, 0 50%, 1 75%, 0 100%)Or simply:
linear(0, 0 50%, 1, 0) CodePen Embed FallbackCool, right? We’re able to create a complex animation with a simple set of keyframes. Not only that, but we can easily adjust the configuration by tweaking the linear() function. This is what we will do for each element to get our sequential animation!
The full animationLet’s get back to our first animation and use the previous linear() value we did before. We will start with two elements.
CodePen Embed FallbackNothing surprising yet. Both elements have the exact same animation, so they animate the same way at the same time. Now, let’s update the linear() function for the first element to have the opposite effect: an animation in the first half, then a delay in the second half.
linear(0, 1, 0 50%, 0)This literally inverts the previous value:
CodePen Embed FallbackTada! We have established a sequential animation with two elements! Are you starting to see the idea? The goal is to do the same with any number (N) of elements. Of course, we are not going to assign a different linear() value for each element — we will do it programmatically.
First, let’s draw a figure to understand what we did for two elements.
When one element is waiting, the other one is animating. We can identify two ranges. Let’s imagine the same with three elements.
This time, we need three ranges. Each element animates in one range and waits in two ranges. Do you see the pattern? For N elements, we need N ranges, and the linear() function will have the following syntax:
linear(0, 0 S, 1, 0 E, 0)The start and the end are equal to 0, which is the initial state of the animation, then we have an animation between S and E. An element will wait from 0% to S, animate from S to E, then wait again from E to 100%. The animation time equals to 100%/N, which means E - S = 100%/N.
The first element starts its animation at the first range (0 * 100%/N), the second element at the second range (1 * 100%/N), the third element at the third range (2 * 100%/N), and so on. S is equal to:
S = (i - 1) * 100%/N…where i is the index of the element.
Now, you may ask, how do we get the value of N and i? The answer is as simple as using the sibling-count()and sibling-index() functions! Again, these are currently supported in Chromium browsers, but we can expect them to roll out in other browsers down the road.
S = calc(100%*(sibling-index() - 1)/sibling-count())And:
E = S + 100%/N E = calc(100%*sibling-index()/sibling-count())We write all this with some good CSS and we are done!
.box { --d: .5s; /* animation duration */ --_s: calc(100%*(sibling-index() - 1)/sibling-count()); --_e: calc(100%*(sibling-index())/sibling-count()); animation: x calc(var(--d)*sibling-count()) infinite linear(0, 0 var(--_s), 1, 0 var(--_e), 0); } @keyframes x { to { background: #F8CA00; scale: .8; } }I used a variable (--d) to control the duration, but it’s not mandatory. I wanted to be able to control the amount of time each element takes to animate. That’s why I multiply it later by N.
CodePen Embed FallbackNow all that’s left is to define your animation. Add as many elements as you want, and watch the result. No more complex keyframes and magic values!
Note: For unknown reasons (probably a bug) you need to register the variables with @property.
More variationsWe can extend the basic idea to create more variations. For example, instead of having to wait for an element to completely end its animation, the next one can already start its own.
CodePen Embed FallbackThis time, I am defining N + 1 ranges, and each element animates in two ranges. The first element will animate in the first and second range, while the second element will animate in the second and third range; hence an overlap of both animations in the second range, etc.
I will not spend too much time explaining this case because it’s one example among many we create, so I let you dissect the code as a small exercise. And here is another one for you to study as well.
CodePen Embed Fallback ConclusionThe linear() function was mainly introduced to create complex easing such as bounce and elastic, but combined with other modern features, it unlocks a lot of possibilities. Through this article, we got a small overview of its potential. I said “small” because we can go further and create even more complex animations, so stay tuned for more articles to come!
Sequential linear() Animation With N Elements originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Embedded AI Apps: Now in ChatGPT
Last week I had a running list of user experience and technical hurdles that made using applications "within" AI models challenging. Then OpenAI's ChatGPT Apps announcement promised to remove most of them. Given how much AI is changing how apps are built and used, I thought it would be worth talking through these challenges and OpenAI's proposed solutions.
Whether you call it a chat app, a remote MCP server app, or an embedded app, when your AI application runs in ChatGPT, the capabilities of ChatGPT become capabilities of your app. ChatGPT can search the web, so can your app. ChatGPT can connect to Salesforce, so can your app. These all sound like great reasons to build an embedded AI app but... there's tradeoffs.
Embedded apps previously had to be added to Claude.ai or ChatGPT (in developer mode) by connecting a remote MCP server, for which the input field could be several clicks deep into a client's settings. That process turned app discovery into a brick wall for most people.
To address this, OpenAI announced a formal app submission and review process with quality standards. Yes, an app store. Get approved and installing your embedded app becomes a one-click action (pending privacy consent flows). No more manual server configs.
If you were able to add an embedded app to a chat client like Claude.ai or ChatGPT, using it was a mostly text-based affair. Embedded apps could not render images much less so, user interface controls. So people were left reading and typing.
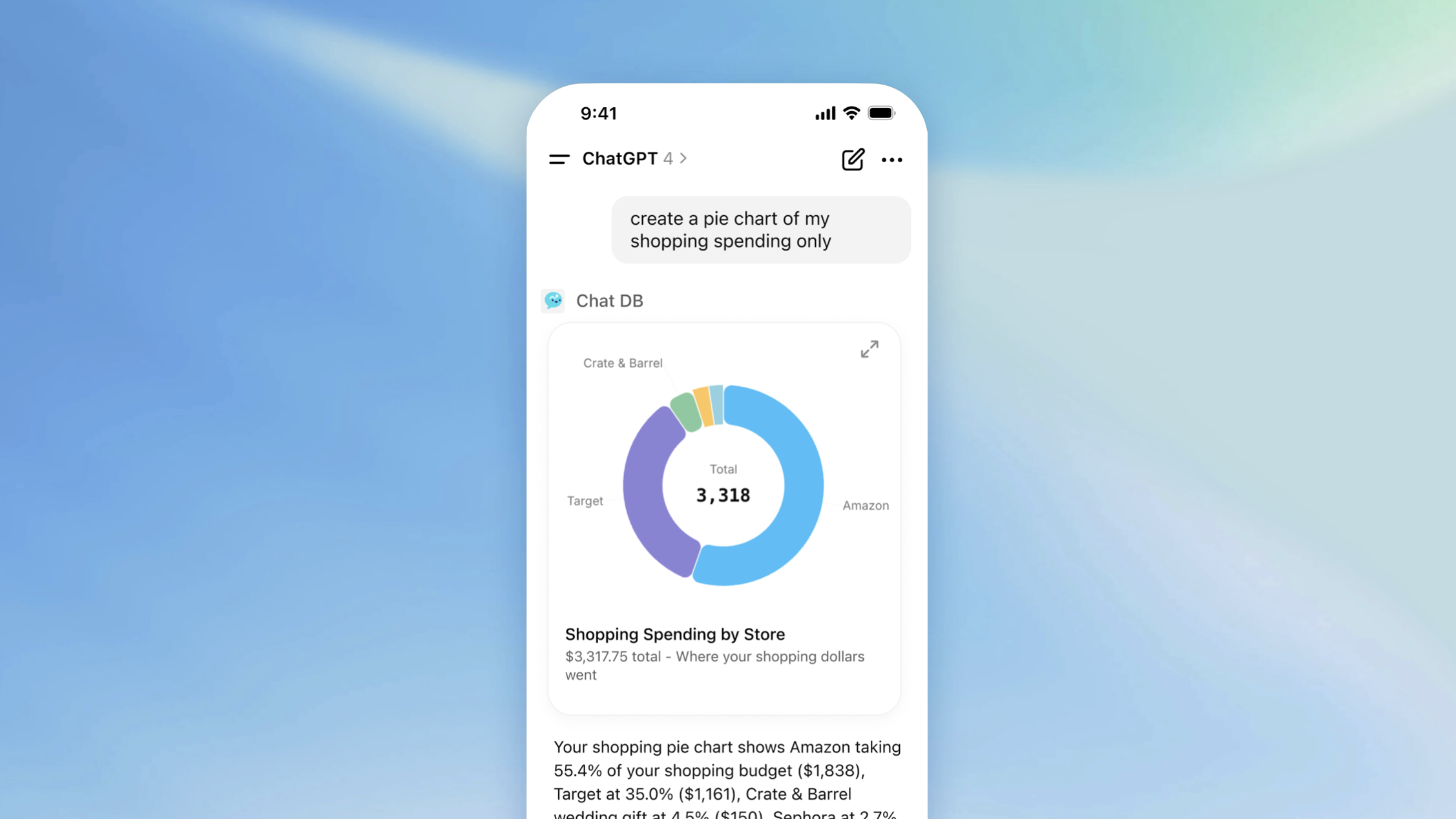{kind=link}
Now, ChatGPT apps are able to render "React components that run inside an iframe" which not only enables inline images, maps, and videos but custom user interface controls as well. These iframes can also run in an expanded full screen mode giving apps more surface area for app-specific UI and in a picture-in-picture (PIP) mode for ongoing sessions.
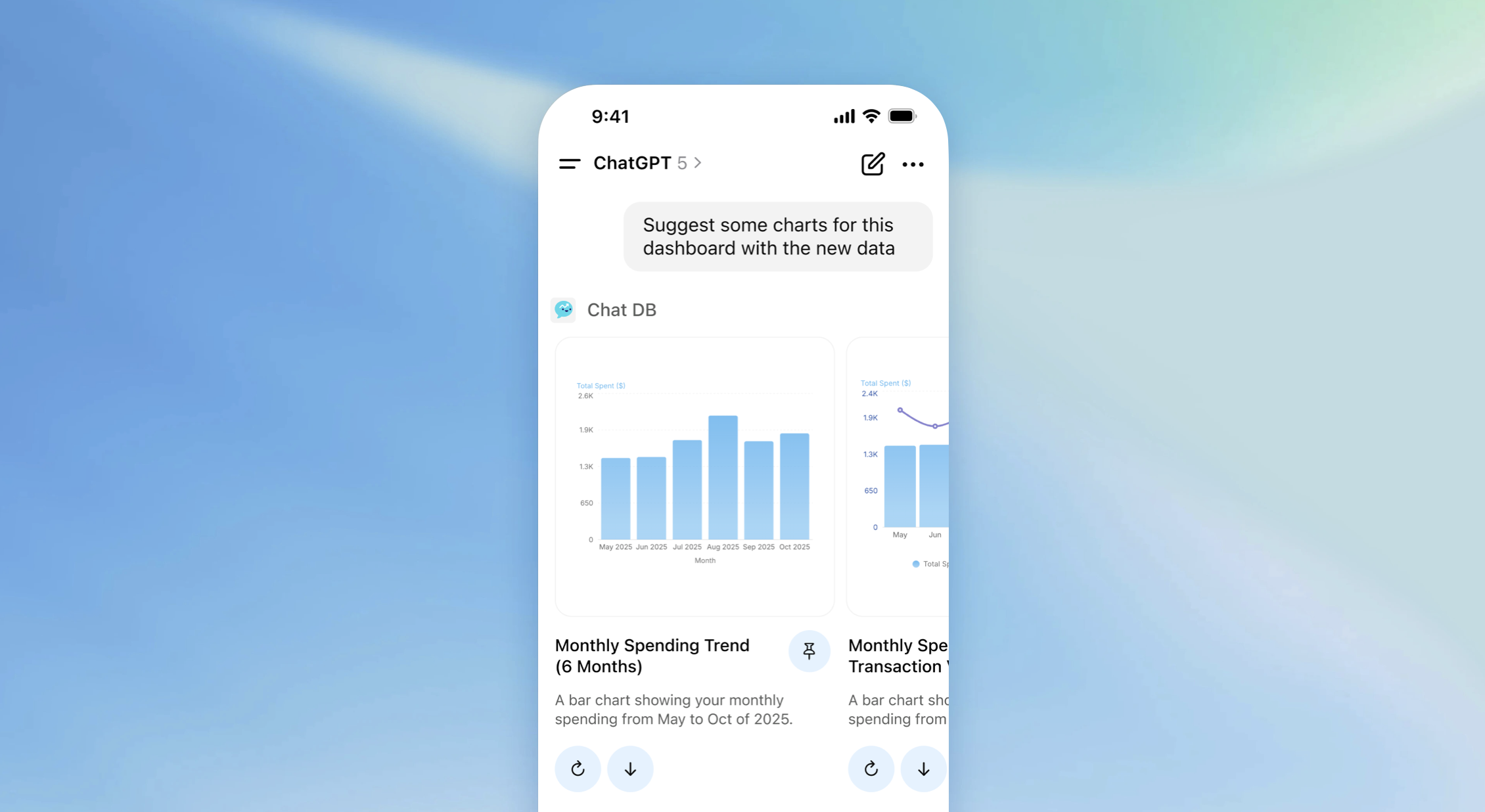{kind=link}
This doesn't mean that embedded app discoverability problems are solved. People still need to either ask for apps by name in ChatGPT, access them by through the "+" button, or rely on the model's ability to decide if/when to use specific apps.
The back and forth between the server running an embedded app and the AI client also has room for improvement. Unlike desktop and mobile operating systems, ChatGPT doesn't (yet) support automatic background refresh, server-initiated notifications, or even passing files (only context) from the front end to a server. These capabilities are pretty fundamental to modern apps, so perhaps support isn't far away.
The tradeoffs involved in building apps for any platform have always been about distribution and technical capabilities or limitations. 800M weekly ChatGPT users is a compelling distribution opportunity and with ChatGPT Apps, a lot of embedded AI app user experience and technical issues have been addressed.
Is this enough to move MCP remote servers from a developer-only protocol to applications that feel like proper software? It's the same pattern from every platform shift: underlying technology first, then the user experience layer that makes it accessible. And there was definitely big steps forward on that last week.
Masonry: Watching a CSS Feature Evolve
You’ve probably heard the buzz about CSS Masonry. You might even be current on the ongoing debate about how it should be built, with two big proposals on the table, one from the Chrome team and one from the WebKit team.
The two competing proposals are interesting in their own right. Chrome posted about its implementation a while back, and WebKit followed it up with a detailed post stating their position (which evolved out of a third proposal from the Technical Architecture Group).
We’ll rehash some of that in this post, but even more interesting to me is that this entire process is an excellent illustration of how the CSS Working Group (CSSWG), browsers, and developers coalesce around standards for CSS features. There are tons of considerations that go into a feature, like technical implementations and backwards compatibility. But it can be a bit political, too.
That’s really what I want to do here: look at the CSS Masonry discussions and what they can teach us about the development of new CSS features. What is the CSSWG’s role? What influence do browsers have? What can learn from the way past features evolved?
Masonry RecapA masonry layout is different than, say Flexbox and Grid, stacking unevenly-sized items along a single track that automatically wraps into multiple rows or columns, depending on the direction. It’s called the “Pinterest layout” for the obvious reason that it’s the hallmark of Pinterest’s feed.
Pinterest’s masonry layoutWe could go deeper here, but talking specifically about CSS Masonry isn’t the point. When Masonry entered CSS Working Group discussions, the first prototype actually came from Firefox back in 2019, based on an early draft that integrated masonry behavior directly into Grid.
The Chrome team followed later with a new display: masonry value, treating it as a distinct layout model. They argued that masonry is a different enough layout from Flexbox and Grid to deserve its own display value. Grid’s defaults don’t line up with how masonry works, so why force developers to learn a bunch of extra Grid syntax? Chrome pushed ahead with this idea and prototyped it in Chrome 140:
.container { display: masonry; grid-template-columns: repeat(auto-fit, minmax(160px, 1fr)); gap: 10px; }Meanwhile, the WebKit team has proposed that masonry should be a subset of Grid, rather than its own display type. They endorsed a newer direction based on a recommendation by the W3C Technical Architecture Group (TAG) built around a concept called Item Flow that unifies flex-flow and grid-auto-flow into a single set of properties. Instead of writing display: masonry, you’d stick with display: grid and use a new item-flow shorthand to collapse rows or columns into a masonry-style layout:
.container { display: grid; grid-template-columns: repeat(auto-fill, minmax(14rem, 1fr)); item-flow: row collapse; gap: 1rem; }The debate here really comes down to mental models and how you think about masonry. WebKit sees it as a natural extension of Grid, not a brand-new system. Their thinking is that developers shouldn’t need to learn an entirely new model when most of it already exists in Grid. With item-flow, you’re not telling the browser “this is a whole new layout system,” you’re more or less adjusting the way elements flow in a particular context.
How CSS Features EvolveThis sort of horse-trading isn’t new. Both Flexbox and Grid went through years of competing drafts before becoming the specs we use today. Flexbox, in particular, had a rocky rollout in the early 2010s. Those who were in the trenches at the time likely remember multiple conflicting syntaxes floating around at once. The initial release had missing gaps and browsers implemented the features differently, leading to all kinds of things, like proprietary properties, experimental releases, and different naming conventions that made the learning curve rather steep, and even Frankenstein-like usage in some cases to get the most browser support.
In other words, Flexbox (nor Grid, for that matter) did not enjoyed a seamless release, but we’ve gotten to a place where the browsers implementations are interoperable with one another. That’s a big deal for developers like us who often juggle inconsistent support for various features. Heck, Rob O’Leary recently published the rabbit hole he traveled trying to use text-wrap: pretty in his work, and that’s considered “Baseline” support that is “widely available.”
But I digress. It’s worth noting that Flexbox faced unique challenges early on, and masonry has benefitted from those lessons learned. I reached out to CSSWG member Tab Atkins-Bittner for a little context since they were heavily involved in editing the Flexbox specification.
“Flexbox was the first of the modern layout algorithms; we made a lot of mistakes and missteps while writing it, because we were trying to figure out how a modern layout model should work.”
In other words, Flexbox was sort of a canary in the coal mine as the CSSWG considered what a modern CSS layout syntax should accomplish. This greatly benefited the work put into defining CSS Grid because a lot of the foundation for things like tracks, intrinsic sizing, and proportions were already tackled. Atkins-Bittner goes on further to explain that the Grid specification process also forced the CSSWG to rethink several of Flexbox’s design choices in the process.
“We found a lot of decisions that made sense on their own in Flexbox needed to be changed if we wanted them to apply more generally.”
This also explains why Flexbox underwent several revisions following its initial release.
It also highlights another key point: CSS features are always evolving. Early debate and iteration are essential because they reduce the need for big breaking changes. Still, some of the Flexbox mistakes (which do happen) became widely adopted. Browsers had widely implemented their approaches and the specification caught up to it while trying to establish a consistent language that helps both user agents and developers implemented and use the features, respectively.
All this to say: Masonry is in a much better spot than Flexbox was at its inception. It benefits from the 15+ years that the CSSWG, browsers, and developers contributed to Flexbox and Grid over that time. The discussions are now less about fixing under-specified details and more about high-level design choices. Hence, novel ideas born from Masonry that combine the features of Flexbox and Grid into the new Item Flow proposal.
It’s messy. And weird. But it’s how things get done.
The CSSWG’s RoleGetting to this point requires process. And in CSS, that process runs through the Working Group. The CSS Working Group (CSSWG) runs on consensus: members debate in the open, weigh pros and cons, and push browsers towards common ground.
Miriam Suzanne, an invited expert with the CSSWG (and CSS-Tricks alumni), describes the process like this:
“The group runs on a consensus model, so everyone has to eventually come to an agreement — or at least agree not to block the most popular path forward.”
But consensus only applies to the specifications. Browsers still decide when and how to those features are shipped, as Suzanne continues:
“Browsers make their own decisions about how strictly they follow a spec, and sometimes release features that haven’t been fully specified. That can lead to situations where the group decides to change a spec years later to match what browsers actually implemented.”
So, while the CSSWG facilitates discussions around features, it can’t actually stop browsers from shipping those features, let alone how they’re implemented. It’s a consensus-driven system, but consensus is only about publishing a specification. In practice, momentum can shift if one vendor is the first to ship or prototype a feature.
In most cases, though, the specification adoption process results in a stronger proposal overall. By the time features ship, the idea is that they’ve already been thoroughly debated, which in theory, reduces the need for significant revisions later that could lead to breaking changes. Backwards compatibility is always at the forefront of CSSWG discussions.
Developer feedback also plays an important role, though there isn’t a single standardized way that it is solicited, collected, or used. For the CSSWG, the csswg-drafts GitHub repo is the primary source of feedback and discussion, while browsers also run their own surveys and gather input through various other channels such as Chrome’s technical discussion groups and Webkit’s mailing lists.
The Bigger PictureBrowsers are in the business of shaping new features. It’s also in their best interest for a number of reasons. Proposing new ideas gives them a seat at the table. Prototyping new features gets developers excited and helps further refine edge cases. Implementing new features (particularly first) gives them a competitive edge in the consumer market.
All that said, prototyping features ahead of consensus is a bit of a tightrope walk.
And that’s where Masonry comes back into the bigger picture. Chrome shipped a prototype of the feature that leans heavily into the first proposal for a new display: masonry value. Other browsers have yet to ship competing prototypes, but have openly discussed their positions, as WebKit did in subsequent blog posts.
At first glance, that might suggest that Chrome is taking a heavy-handed approach to tip the scales in its favorable direction. But there’s a lot to like about prototyping features because it’s proof in the pudding for real-world uses by allowing developers early access to experiment.
Atkins-Bittner explains it nicely:
“Prototyping before consensus is an important part of building consensus. You get early implementation feedback, you get more eyes on the problem (the implementing engineers rather than just the spec authors).”
This kind of “soft” commit moves conversations forward while leaving room to change course, if needed, based on real-world use.
But there’s obviously a tension here as well. Browsers may be custodians of web standards and features, but they’re still employed by massive companies that are selling a product at the end of the day. It’s easy to get cynical. And political.
In theory, though, allowing browsers to voluntarily adopt features gives everyone choice: browsers compete in the market based on what they implement, developers gain new features that push the web further, and everyone gets to choose the browser that best fits their browsing needs.
If one company controls access to a huge share of users, however, those choices feel less accessible. Standards often get shaped just as much by market power as by technical merit.
Where We’re AtAt the end of the day, standards get shaped by a mix of politics, technical trade-offs, and developer feedback. Consensus is messy, and it’s rarely about one side “winning.” With masonry, it might look like Google got its way, but in reality the outcome reflects input from both proposals, plus ideas from the wider community.
As of this writing:
- Masonry will be a new display type, but must include the word “grid” in the name. The exact keyword is still being debated.
- The CSSWG has resolved to proceed with the proposed **item-flow** approach.
- Grid will be used for layout templates and explicitly placing items in them.
- Some details, like a possible shorthand syntax and track listing defaults, are still being discussed.
This is a big topic, one that goes much deeper and further than we’ve gone here. While working on this article, a few others popped up that are very much worth your time to see the spectrum of ideas and opinions about the CSS standards process:
- Alex Russell’s post about the standards adoption process in browsers.
- Rob O’Leary’s article about struggling with text-wrap: pretty, explaining that “Baseline” doesn’t always mean consistent support in practice.
- David Bushell’s piece about the WHATWG. It isn’t about the CSSWG specifically, but covers similar discussions on browser politics and standards consensus.
Masonry: Watching a CSS Feature Evolve originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
We Completely Missed width/height: stretch
The stretch keyword, which you can use with width and height (as well as min-width, max-width, min-height, and max-height, of course), was shipped in Chromium web browsers back in June 2025. But the value is actually a unification of the non-standard -webkit-fill-available and -moz-available values, the latter of which has been available to use in Firefox since 2008.
The issue was that, before the @supports at-rule, there was no nice way to implement the right value for the right web browser, and I suppose we just forgot about it after that until, whoops, one day I see Dave Rupert casually put it out there on Bluesky a month ago:
Layout pro Miriam Suzanne recorded an explainer shortly thereafter. It’s worth giving this value a closer look.
What does stretch do?The quick answer is that stretch does the same thing as declaring 100%, but ignores padding when looking at the available space. In short, if you’ve ever wanted 100% to actually mean 100% (when using padding), stretch is what you’re looking for:
div { padding: 3rem 50vw 3rem 1rem; width: 100%; /* 100% + 50vw + 1rem, causing overflow */ width: stretch; /* 100% including padding, no overflow */ } CodePen Embed FallbackThe more technical answer is that the stretch value sets the width or height of the element’s margin box (rather than the box determined by box-sizing) to match the width/height of its containing block.
Note: It’s never a bad idea to revisit the CSS Box Model for a refresher on different box sizings.
And on that note — yes — we can achieve the same result by declaring box-sizing: border-box, something that many of us do, as a CSS reset in fact.
*, ::before, ::after { box-sizing: border-box; }I suppose that it’s because of this solution that we forgot all about the non-standard values and didn’t pay any attention to stretch when it shipped, but I actually rather like stretch and don’t touch box-sizing at all now.
Yay stretch, nay box-sizingThere isn’t an especially compelling reason to switch to stretch, but there are several small ones. Firstly, the Universal selector (*) doesn’t apply to pseudo-elements, which is why the CSS reset typically includes ::before and ::after, and not only are there way more pseudo-elements than we might think, but the rise in declarative HTML components means that we’ll be seeing more of them. Do you really want to maintain something like the following?
*, ::after, ::backdrop, ::before, ::column, ::checkmark, ::cue (and ::cue()), ::details-content, ::file-selector-button, ::first-letter, ::first-line, ::grammar-error, ::highlight(), ::marker, ::part(), ::picker(), ::picker-icon, ::placeholder, ::scroll-button(), ::scroll-marker, ::scroll-marker-group, ::selection, ::slotted(), ::spelling-error, ::target-text, ::view-transition, ::view-transition-image-pair(), ::view-transition-group(), ::view-transition-new(), ::view-transition-old() { box-sizing: border-box; }Okay, I’m being dramatic. Or maybe I’m not? I don’t know. I’ve actually used quite a few of these and having to maintain a list like this sounds dreadful, although I’ve certainly seen crazier CSS resets. Besides, you might want 100% to exclude padding, and if you’re a fussy coder like me you won’t enjoy un-resetting CSS resets.
Animating to and from stretchOpinions aside, there’s one thing that box-sizing certainly isn’t and that’s animatable. If you didn’t catch it the first time, we do transition to and from 100% and stretch:
CodePen Embed FallbackBecause stretch is a keyword though, you’ll need to interpolate its size, and you can only do that by declaring interpolate-size: allow-keywords (on the :root if you want to activate interpolation globally):
:root { /* Activate interpolation */ interpolate-size: allow-keywords; } div { width: 100%; transition: 300ms; &:hover { width: stretch; } }The calc-size() function wouldn’t be useful here due to the web browser support of stretch and the fact that calc-size() doesn’t support its non-standard alternatives. In the future though, you’ll be able to use width: calc-size(stretch, size) in the example above to interpolate just that specific width.
Web browser supportWeb browser support is limited to Chromium browsers for now:
- Opera 122+
- Chrome and Edge 138+ (140+ on Android)
Luckily though, because we have those non-standard values, we can use the @supports at-rule to implement the right value for the right browser. The best way to do that (and strip away the @supports logic later) is to save the right value as a custom property:
:root { /* Firefox */ @supports (width: -moz-available) { --stretch: -moz-available; } /* Safari */ @supports (width: -webkit-fill-available) { --stretch: -webkit-fill-available; } /* Chromium */ @supports (width: stretch) { --stretch: stretch; } } div { width: var(--stretch); }Then later, once stretch is widely supported, switch to:
div { width: stretch; } In a nutshellWhile this might not exactly win Feature of the Year awards (I haven’t heard a whisper about it), quality-of-life improvements like this are some of my favorite features. If you’d rather use box-sizing: border-box, that’s totally fine — it works really well. Either way, more ways to write and organize code is never a bad thing, especially if certain ways don’t align with your mental model.
Plus, using a brand new feature in production is just too tempting to resist. Irrational, but tempting and satisfying!
We Completely Missed width/height: stretch originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.
Let the AI do the Onboarding
Anyone that's designed software has likely had to address the "empty state" problem. While an application can create useful stuff, getting users over the initial hurdle of creation is hard. With today's technology, however, AI models can cross the creation chasm so people don't have.
If you're designing a spreadsheet application, you'll need a "new spreadsheet" page. If you're designing a presentation tool, you'll need an empty state for new presentations. Document editors, design tools, project management apps... they all face the same hurdle: how do you help people get started when they're staring at a blank canvas?
{kind=link}
Designers have tried to address the creation chasm many times resulting in a bunch of common patterns you'll encounter in any software app you use.
- Coach marks that educate people on what they can change and how
- Templates that provide pre-built starting points
- Tours that walk users through key features
- Overlays that highlight important interface elements
- Videos that demonstrate how to use an application
{kind=link}
These approaches require people to learn first, then act. But in reality most of us just jump right into doing and only fall-back on learning if what we try doesn't work. Shockingly, asking people to read the manual first doesn't work.
But with the current capabilities of AI models, we can do something different. AI can model how to use a product by actually going through the process of creating something and letting people watch. From there, people can just tweak the result to get closer to what they want. AI does the creation, people do the curation.
Rather than learning then doing, people observe then refine. Instead of starting from nothing, they start from something an AI builds for them and making it their own. Instead of teaching people how to create, we show them creation in action. In other words, the AI does the (onboarding) work.
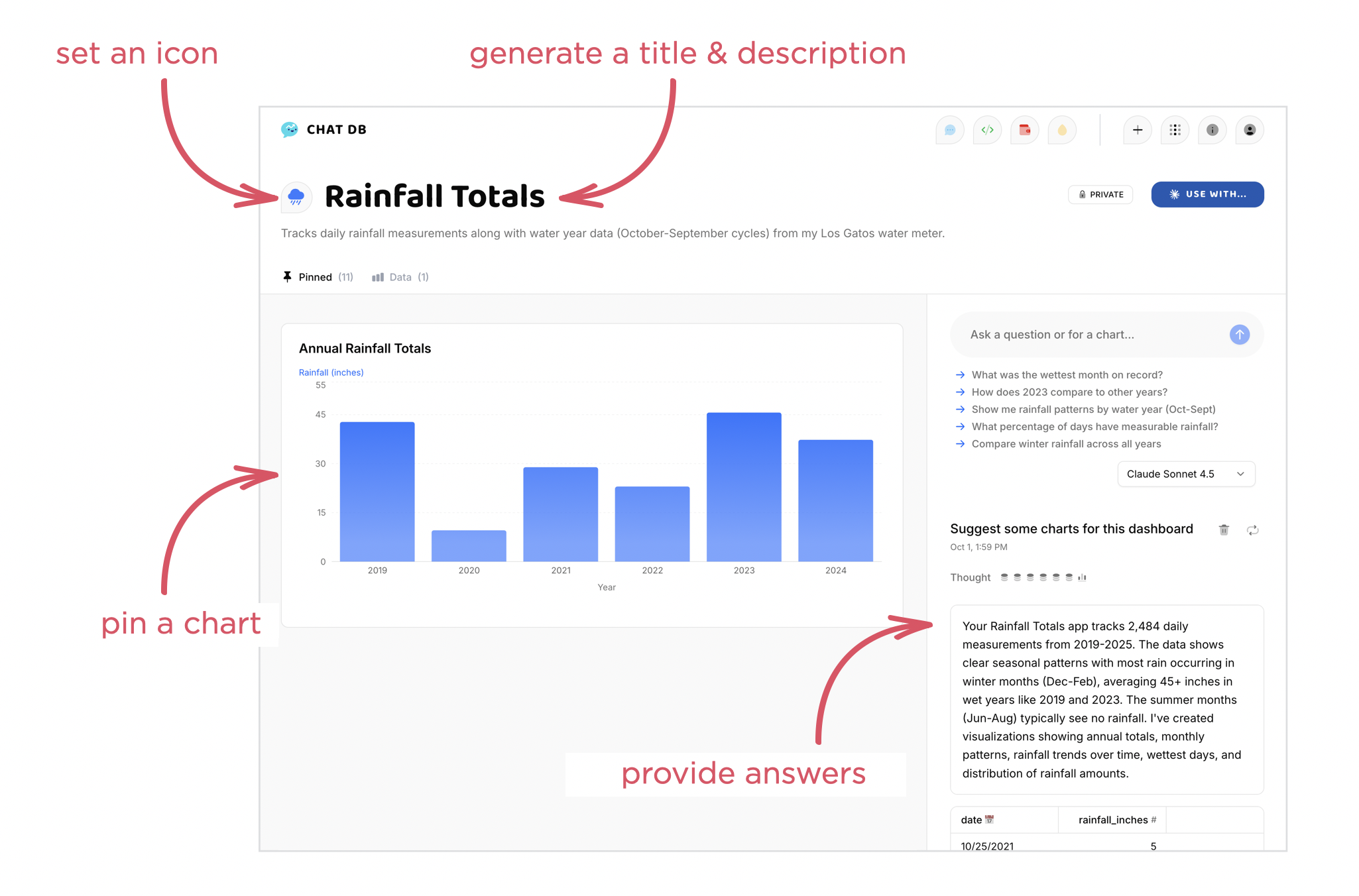{kind=link}
You can see this in action on ChatDB which allows people to instantly understand, visualize, and share data. When you upload a set of data to ChatDB it, will:
- make a dashboard for you
- name your dashboard
- write a description for it
- pick an icon and color set for it
- make you a series of initial charts
- pin one to your dashboard
All this happens in front of your eyes making it clear how ChatDB works and what you can do with it, no onboarding required.
Once your dashboard is made, it's trivial to edit the title (just click and type), change the icon, colors, and more. AI gives you the starting point and you take it from there. Try it out yourself.
With this approach, we can shift from applications that tell people how to use them to applications that show people what they can do by doing it for them. The traditional empty state problem transforms from "how do we help people start?" to "how do we help people refine?" And software shows people what's possible through action rather than instruction.
The thing about contrast-color
One of our favorites, Andy Clarke, on the one thing keeping the CSS contrast-color() function from true glory:
For my website design, I chose a dark blue background colour (#212E45) and light text (#d3d5da). This colour is off-white to soften the contrast between background and foreground colours, while maintaining a decent level for accessibility considerations.
But here’s the thing. The contrast-color() function chooses either white for dark backgrounds or black for light ones. At least to my eyes, that contrast is too high and makes reading less comfortable, at least for me.
Word. White and black are two very safe colors to create contrast with another color value. But the amount of contrast between a solid white/black and any other color, while offering the most contrast, may not be the best contrast ratio overall.
This was true when added a dark color scheme to my personal website. The contrast between the background color, a dark blue (hsl(238.2 53.1% 12.5%), and solid white (#fff) was too jarring for me.
To tone that down, I’d want something a little less opaque than what, say hsl(100 100% 100% / .8), or 20% lighter than white. Can’t do that with contrast-color(), though. That’s why I reach for light-dark() instead:
body { color: light-dark(hsl(238.2 53.1% 12.5%), hsl(100 100% 100% / .8)); }Will contrast-color() support more than a black/white duo in the future? The spec says yes:
Future versions of this specification are expected to introduce more control over both the contrast algorithm(s) used, the use cases, as well as the returned color.
I’m sure it’s one of those things that ‘s easier said than done, as the “right” amount of contrast is more nuanced than simply saying it’s a ratio of 4.5:1. There are user preferences to take into account, too. And then it gets into weeds of work being done on WCAG 3.0, which Danny does a nice job summarizing in a recent article detailing the shortcomings of contrast-color().
The thing about contrast-color originally published on CSS-Tricks, which is part of the DigitalOcean family. You should get the newsletter.