LukeW

AI Has Flipped Software Development
For years, it's been faster to create mockups and prototypes of software than to ship it to production. As a result, software design teams could stay "ahead" of engineering. Now AI coding agents make development 10x faster, flipping the traditional software development process on its head.
In my thirty years of working on software, the design teams I was part of were typically operating "out ahead" of our software development counterparts. Unburdened by existing codebases, technical debt, performance, and infrastructure limitations, designers could work quickly in mockups, wireframes, and even prototypes to help envision what we could or should build before time and effort was invested into actually building it.
While some software engineering teams could ship in days, in most (especially larger) organizations, building new features or redesigning apps could take months if not quarters or years. So there was plenty of time for designers to explore and iterate. This was also reflected in the ratio of designers to developers in most companies: an average of one designer for every twenty engineers.
When designs did move to the production engineering phase, there'd (hopefully) be a bunch of back and forth to resolve unanswered questions, new issues that came up, or changing requirements. A lot of this burden fell on engineering as they encountered edge cases, things missing in specs, cross-device capability differences, and more. What it added up to though, was that the process to build and launch something often took longer than the process to design it.
AI coding tools change this dynamic. Across several of our companies, software development teams are now "out ahead" of design. To be more specific, collaborating with AI agents (like Augment Code) allows software developers to move from concept to working code 10x faster. This means new features become code at a fast and furious pace.
{kind=link}
When software is coded this way, however, it (currently at least) lacks UX refinement and thoughtful integration into the structure and purpose of a product. This is the work that designers used to do upfront but now need to "clean up" afterward. It's like the development process got flipped around. Designers used to draw up features with mockups and prototypes, then engineers would have to clean them up to ship them. Now engineers can code features so fast that designers are ones going back and cleaning them up.
So scary time to be a designer? No. Awesome time to be a designer. Instead of waiting for months, you can start playing with working features and ideas within hours. This allows everyone, whether designer or engineer, an opportunity to learn what works and what doesn’t. At its core rapid iteration improves software and the build, use/test, learn, repeat loop just flipped, it didn't go away.
In his Designing Perplexity talk at Sutter Hill Ventures, Henry Modisett described this new state as "prototype to productize" rather than "design to build". Sounds right to me.
AI Has Flipped Software Development
For years, it's been faster to create mockups and prototypes of software than to ship it to production. As a result, software design teams could stay "ahead" of engineering. Now AI coding agents make development 10x faster, flipping the traditional software development process on its head.
In my thirty years of working on software, the design teams I was part of were typically operating "out ahead" of our software development counterparts. Unburdened by existing codebases, technical debt, performance, and infrastructure limitations, designers could work quickly in mockups, wireframes, and even prototypes to help envision what we could or should build before time and effort was invested into actually building it.
While some software engineering teams could ship in days, in most (especially larger) organizations, building new features or redesigning apps could take months if not quarters or years. So there was plenty of time for designers to explore and iterate. This was also reflected in the ratio of designers to developers in most companies: an average of one designer for every twenty engineers.
When designs did move to the production engineering phase, there'd (hopefully) be a bunch of back and forth to resolve unanswered questions, new issues that came up, or changing requirements. A lot of this burden fell on engineering as they encountered edge cases, things missing in specs, cross-device capability differences, and more. What it added up to though, was that the process to build and launch something often took longer than the process to design it.
AI coding tools change this dynamic. Across several of our companies, software development teams are now "out ahead" of design. To be more specific, collaborating with AI agents (like Augment Code) allows software developers to move from concept to working code 10x faster. This means new features become code at a fast and furious pace.
When software is coded this way, however, it (currently at least) lacks UX refinement and thoughtful integration into the structure and purpose of a product. This is the work that designers used to do upfront but now need to "clean up" afterward. It's like the development process got flipped around. Designers used to draw up features with mockups and prototypes, then engineers would have to clean them up to ship them. Now engineers can code features so fast that designers are ones going back and cleaning them up.
So scary time to be a designer? No. Awesome time to be a designer. Instead of waiting for months, you can start playing with working features and ideas within hours. This allows everyone, whether designer or engineer, an opportunity to learn what works and what doesn’t. At its core rapid iteration improves software and the build, use/test, learn, repeat loop just flipped, it didn't go away.
In his Designing Perplexity talk at Sutter Hill Ventures, Henry Modisett described this new state as "prototype to productize" rather than "design to build". Sounds right to me.
Designing Software for AI Agents
From making apps, browsing the Web, to creating files, today's AI agents today can take on an increasing number of computing tasks on their own. But the software underlying these capabilities, wasn't made for agents. It was designed and built for people to use. As such there's an opportunity, and perhaps an increasing need, to rethink these systems for agent use.
When building agent-based AI applications, you'll likely butt up against a number of situations where existing software isn't optimized for what thinking machines can do. For instance, Web search. Nearly every agent-based AI application makes use of information on the Web to get things done. But Web Search APIs weren't written with agents in mind.
They provide a limited number of search results and a condensed snippet format that lines up more with how people use Web search interfaces. We get a page of ten blue links and scan them to decide which one to click. But AI agents aren't people. Not only can they make sense of many more search results at once, but their performance usually improves with larger document summaries and contents. People on the other hand, are unlikely to read through all search results before making a decision. So search APIs could certainly be rethought for agents.
Similarly, when agents are developing applications or collecting data, they can make use of databases. But once again databases were designed and built for people to use not AI agents. And once again they can be rethought for agents, which is what we did with our most recent launch: AgentDB.
{kind=link}
Agents can (and do) produce 1000x more databases than people every day, so the process of spinning up and managing any database for an agent needs to be as easy and maintenance-free as possible. Most of the databases AI agents create will be short-lived after serving their initial purpose. But some databases will be used again and others still will be used regularly.
With this kind of volume costs can become an issue, so keeping that many databases available needs to be as cost effective as possible. Last but not least, the content of databases needs to work well as context for AI models so agents can use this data as part of their tasks.
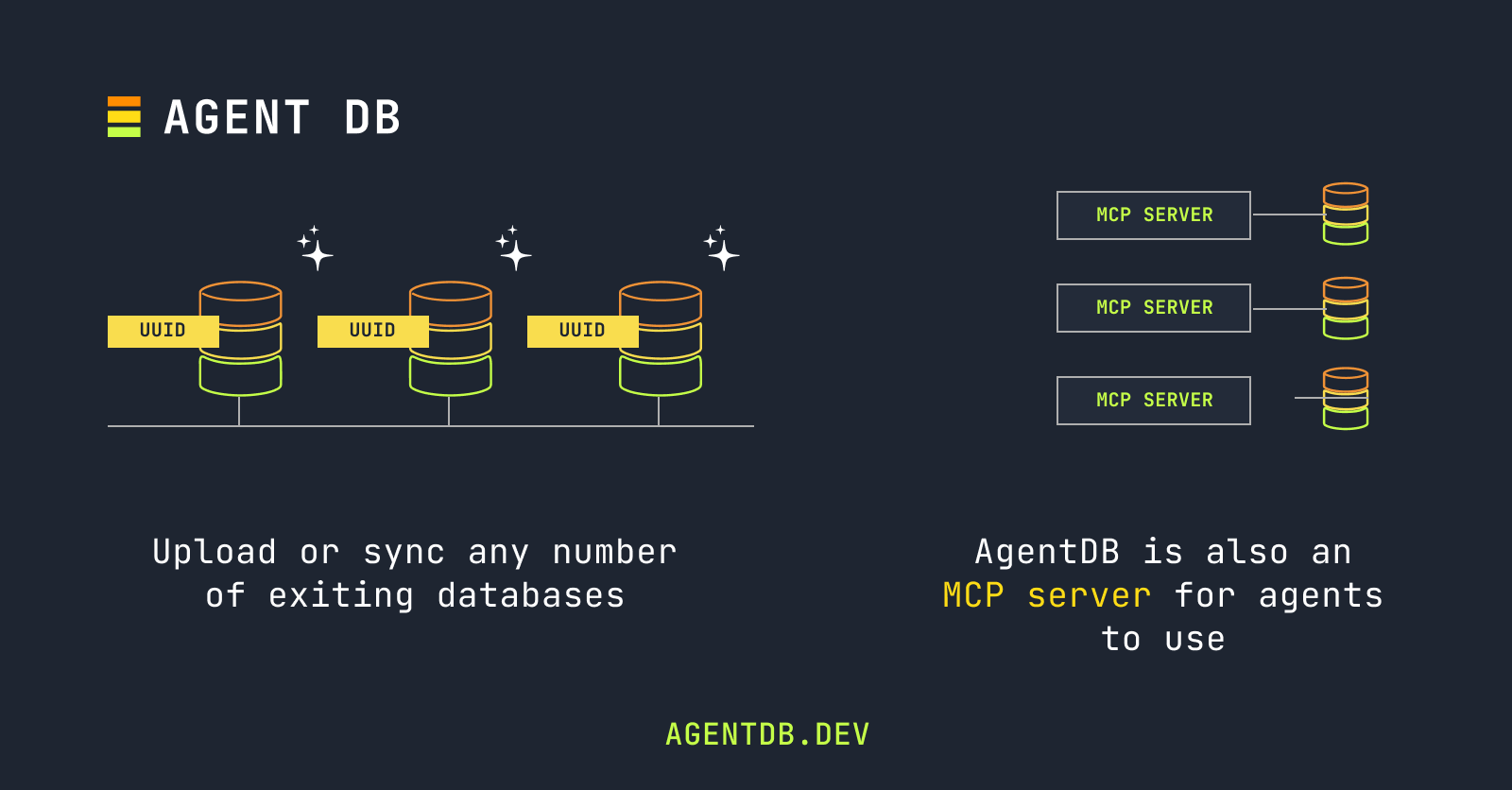
AgentDB is a database system designed around these considerations. With AgentDB, creating a database only requires a Universally Unique Identifier (UUID). There's no setup or configuration step. So whenever an AI agent decides it needs a database, it has one simply by creating a UUID. No forms or set-up wizards involved.
{kind=link}
Databases in AgentDB are stored as files not hosted services requiring compute and maintenance. If an AI agent needs to query a database or append to it, it can. But if it never needs to access it again, the database is just a file. That means you're only paying for the cost of storage to keep it around and because AgentDB databases are just files, they scale. Meaning they can easily keep up with the scale of AI agents.
{kind=link}
To make data within each AgentDB database easily accessible as context for AI models, every AgentDB account is also an MCP server. This makes the data portable across AI applications as long as they support MCP server connections (which most do).
{kind=link}
Altogether this example illustrates how even the most fundamental software infrastructure systems, like databases, can be rethought for the age of AI. The AgentDB database system doesn't look like a hosted database as a service solution because it's not designed and built for database admins and back-end developers. It's built for today's thinking machines.
And as agents take on more computing tasks for people, it won't be the only software made with agents as first class users.
Designing Software for AI Agents
From making apps, browsing the Web, to creating files, today's AI agents today can take on an increasing number of computing tasks on their own. But the software underlying these capabilities, wasn't made for agents. It was designed and built for people to use. As such there's an opportunity, and perhaps an increasing need, to rethink these systems for agent use.
When building agent-based AI applications, you'll likely butt up against a number of situations where existing software isn't optimized for what thinking machines can do. For instance, Web search. Nearly every agent-based AI application makes use of information on the Web to get things done. But Web Search APIs weren't written with agents in mind.
They provide a limited number of search results and a condensed snippet format that lines up more with how people use Web search interfaces. We get a page of ten blue links and scan them to decide which one to click. But AI agents aren't people. Not only can they make sense of many more search results at once, but their performance usually improves with larger document summaries and contents. People on the other hand, are unlikely to read through all search results before making a decision. So search APIs could certainly be rethought for agents.
Similarly, when agents are developing applications or collecting data, they can make use of databases. But once again databases were designed and built for people to use not AI agents. And once again they can be rethought for agents, which is what we did with our most recent launch: AgentDB.
Agents can (and do) produce 1000x more databases than people every day, so the process of spinning up and managing any database for an agent needs to be as easy and maintenance-free as possible. Most of the databases AI agents create will be short-lived after serving their initial purpose. But some databases will be used again and others still will be used regularly.
With this kind of volume costs can become an issue, so keeping that many databases available needs to be as cost effective as possible. Last but not least, the content of databases needs to work well as context for AI models so agents can use this data as part of their tasks.
AgentDB is a database system designed around these considerations. With AgentDB, creating a database only requires a Universally Unique Identifier (UUID). There's no setup or configuration step. So whenever an AI agent decides it needs a database, it has one simply by creating a UUID. No forms or set-up wizards involved.
Databases in AgentDB are stored as files not hosted services requiring compute and maintenance. If an AI agent needs to query a database or append to it, it can. But if it never needs to access it again, the database is just a file. That means you're only paying for the cost of storage to keep it around and because AgentDB databases are just files, they scale. Meaning they can easily keep up with the scale of AI agents.
To make data within each AgentDB database easily accessible as context for AI models, every AgentDB account is also an MCP server. This makes the data portable across AI applications as long as they support MCP server connections (which most do).
Altogether this example illustrates how even the most fundamental software infrastructure systems, like databases, can be rethought for the age of AI. The AgentDB database system doesn't look like a hosted database as a service solution because it's not designed and built for database admins and back-end developers. It's built for today's thinking machines.
And as agents take on more computing tasks for people, it won't be the only software made with agents as first class users.
Context Management UI in AI Products
They say context is king and that's certainly true in AI products where the content, tools, and instructions applications provide to AI models shape their behavior and subsequent results. But if context is so critical, how do we allow people to understand and manage it when interacting with AI-driven software?
In AI products, there's a lot of stuff that could be in context (provided to an AI model as part of its instructions) at any given point, but not everything will be in context all the time because AI models have context limits. So when getting results from AI products, people aren't sure if or how much they should trust them. Was the right information used to answer my question? Did the model hallucinate or use the wrong information?
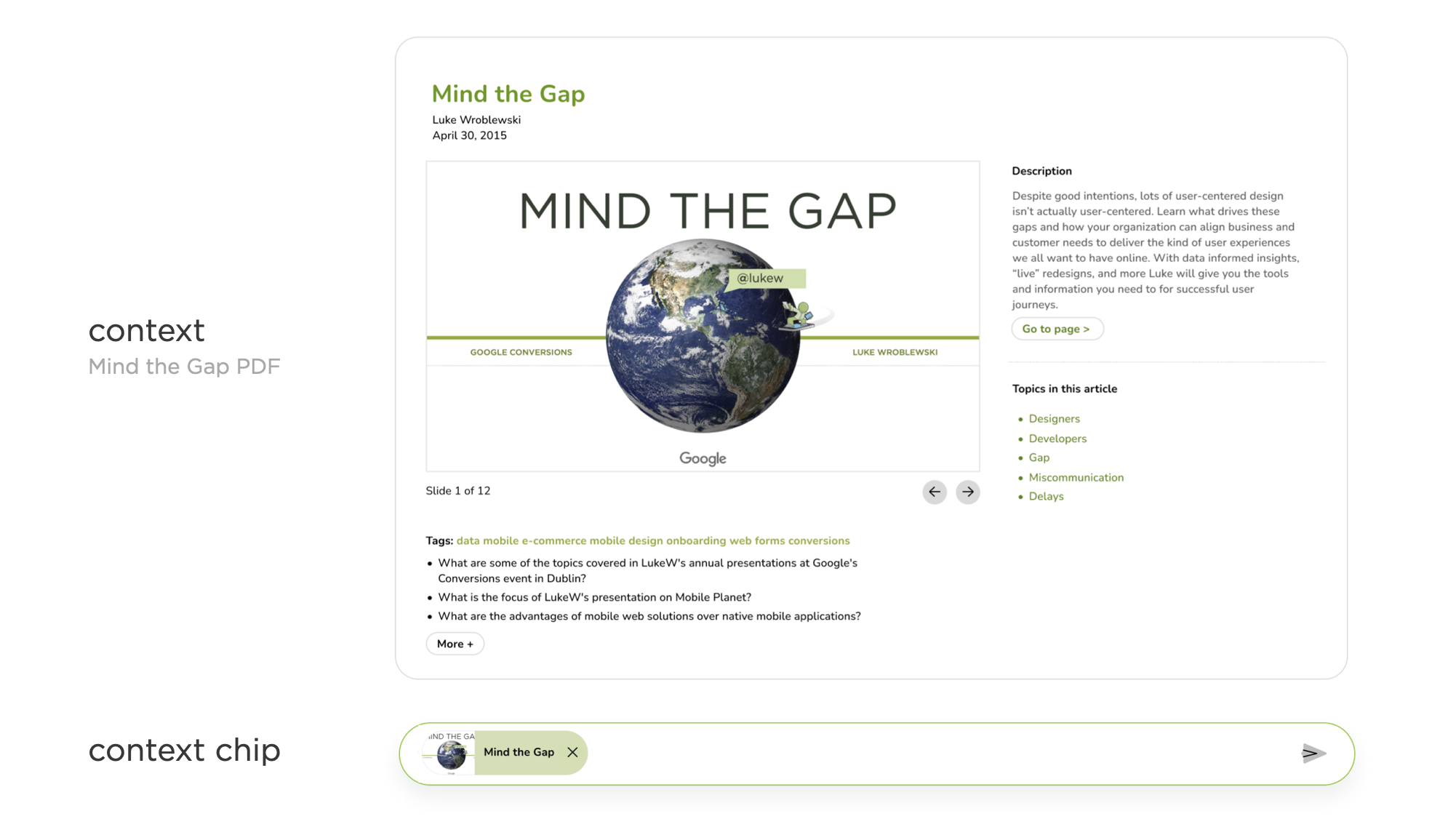
When I launched my personal AI two years ago, context was much simpler than it is today. In Ask LukeW, when people ask a question about digital product design, the system searches through my writings, finds and puts the most relevant bits into context for AI models to use and reference, then cities them in the results people see. This is pretty transparent in the interface: the articles, videos, audio, and PDFs used are shown on the right with citations within each response to where these files were used the most.
{kind=link}
The most complicated things get in Ask LukeW is when someone opens one of these citied articles, videos, or PDFs to view its full contents. In this case, a small "context chip" is added to the question bar to make clear questions can be asked of just this file. In other words, the file is the primary thing in context. If someone wants to ask a question of the whole corpus of my writings and talks again, they can simply click on the X that removes this context constraint and the chip disappears from the question bar. You can try this out yourself here.
{kind=link}
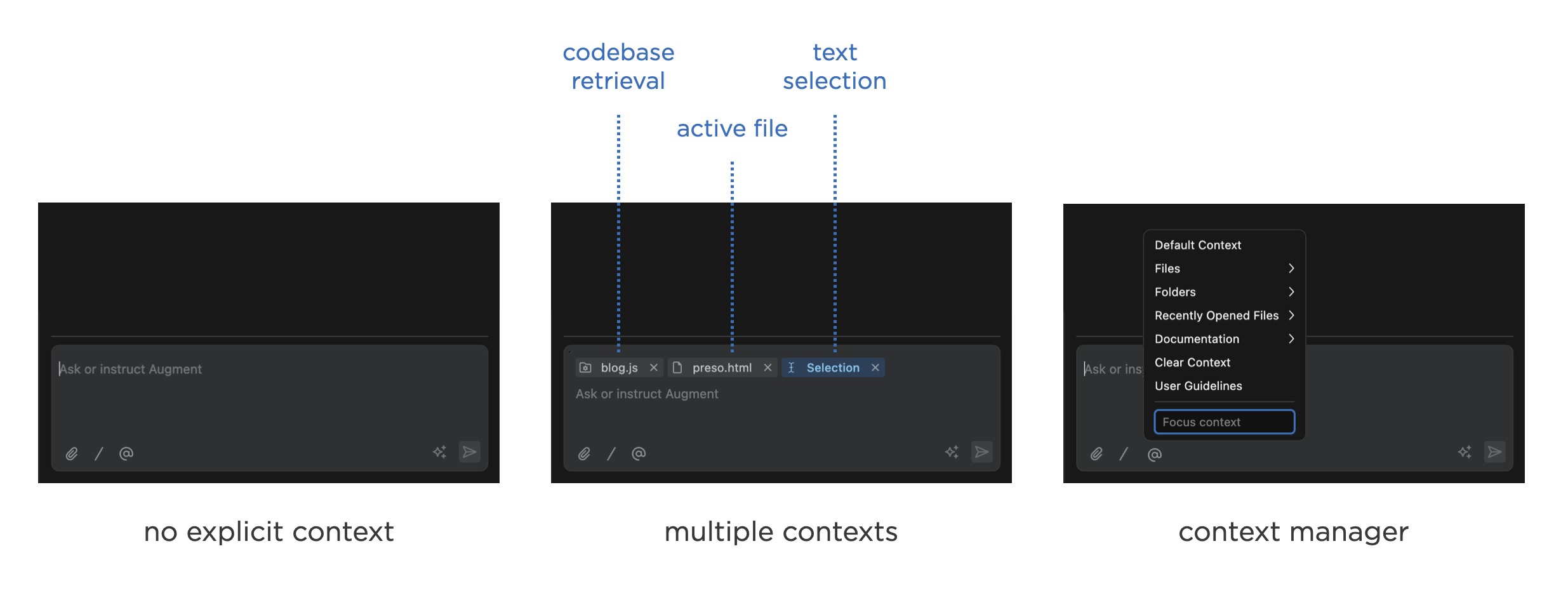
Context chips are pretty common in AI products today because they're a relatively easy way to both give people a sense of what's influencing an AI model's replies and to add or remove it. When what's in context expands, however, they don't scale very well. For example, Augment Code uses context chips for retrieval systems, active files, selected text, and more.
{kind=link}
Using a context chip to display everything influencing an AI model's response begins to break down when many things (especially different things) are in context. Displaying them all eats up valuable space in the UI and requires that their names or identifiers are truncated to fit. That kind of defeats the purpose of "showing you what's in context". Also when AI products do automatic context retrieval like Augment Code's context retrieval engine: does that always show up as a chip? or should people not worry about it and trust the system is finding and putting the right things into context?
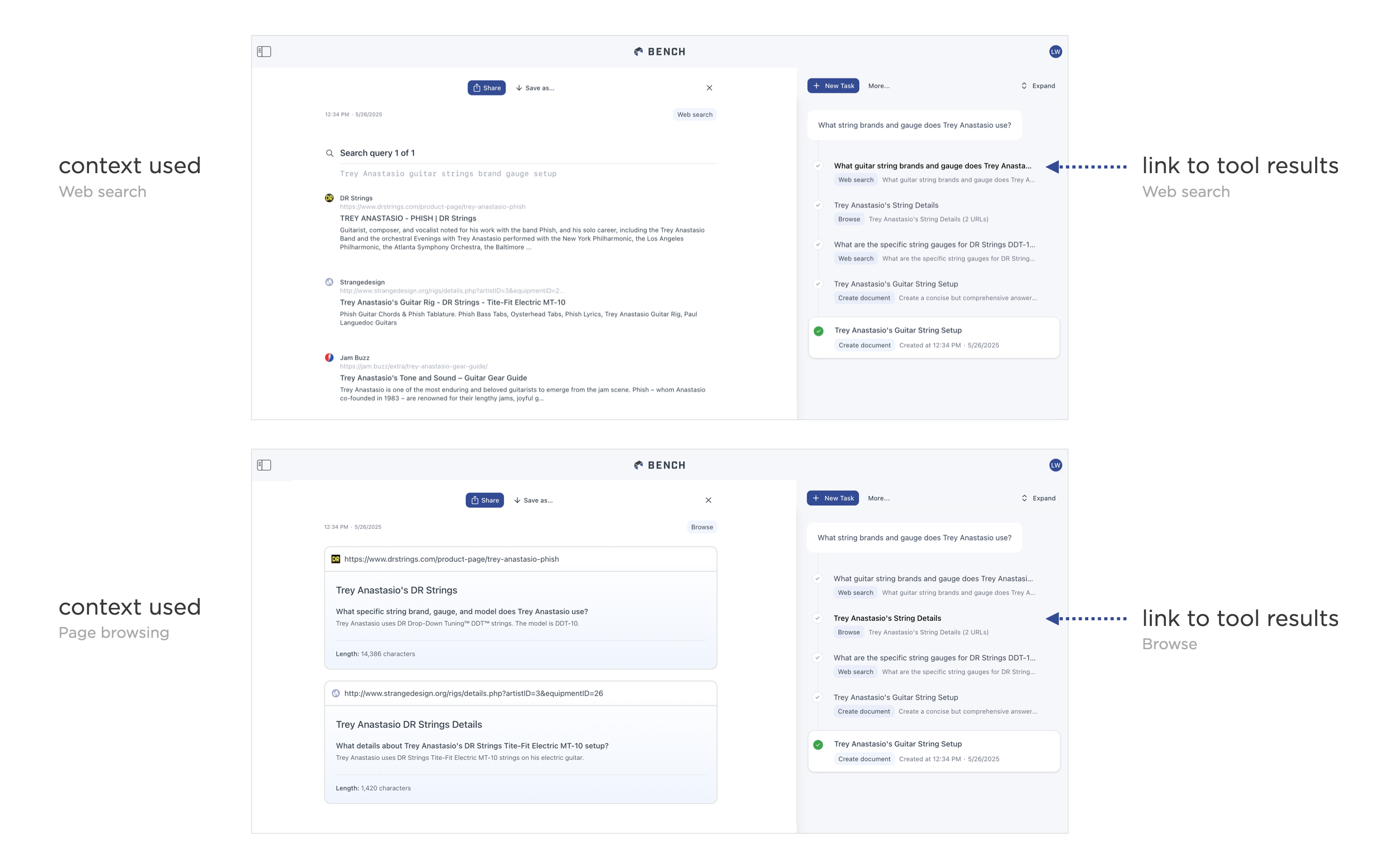
With AI products using agents these issues are compounded because each tool call an agent makes can retrieve context in different ways or multiple times. So showing every bit of context found or created by tools as a context chip quickly breaks down. To account for this in earlier versions of Bench, we showed the context from tools used by agents as it was being created. But this turned out to be a jarring experience as the context would show up then go away when the next tool's context arrived (as you can see in the video).
Since then, we've moved to showing an agent's process of creating something as condensed steps with links to the context in each step. So people can click on any given steps to see the context a tool either found or created. But that context isn't being automatically flashed in front of them as it's made. This lets people focus on the output and only dig into the process when they want to understand what led to the output.
{kind=link}
This approach becomes even more relevant with agent orchestration. When agents can make use of agents themselves, you end up with nested amounts of context. Told you things were a lot simpler two years ago! In these cases, Bench just shows the collective context combined from multiple tool calls in one link. This allows people to examine what cumulative context was created by sub agents. But importantly this combined context is treated the same way - whether it comes from a single tool or a subagent that uses multiple tools.
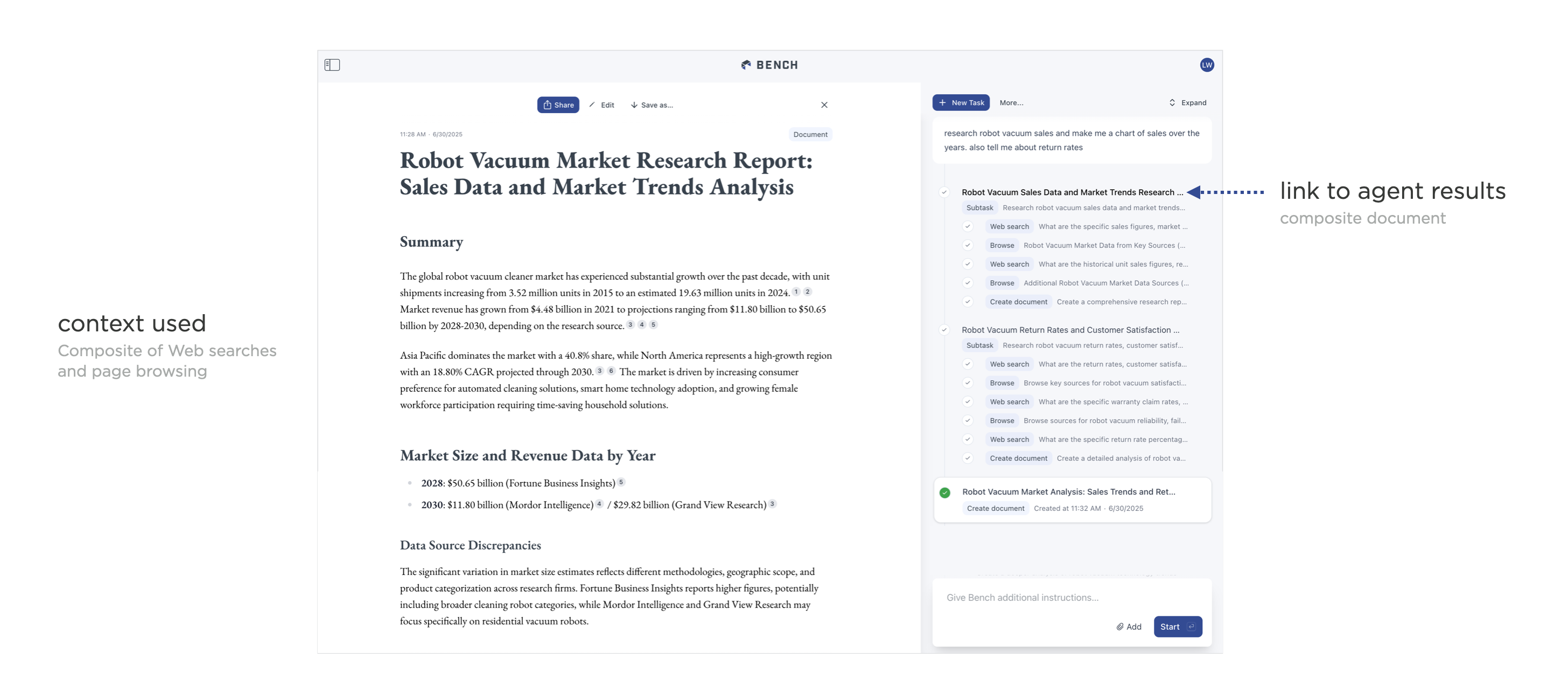{kind=link}
While making context understood and manageable feels like the right thing to provide transparency and control, increasingly people seem to focus more on the output of AI products and less on the process that created them. Only when things don't seem "right" do they dig into the kinds of process timelines and context links that Bench provides. So if people become even more confident using AI products, we might see context management UIs with even less presence.
Context Management UI in AI Products
They say context is king and that's certainly true in AI products where the content, tools, and instructions applications provide to AI models shape their behavior and subsequent results. But if context is so critical, how do we allow people to understand and manage it when interacting with AI-driven software?
In AI products, there's a lot of stuff that could be in context (provided to an AI model as part of its instructions) at any given point, but not everything will be in context all the time because AI models have context limits. So when getting results from AI products, people aren't sure if or how much they should trust them. Was the right information used to answer my question? Did the model hallucinate or use the wrong information?
When I launched my personal AI two years ago, context was much simpler than it is today. In Ask LukeW, when people ask a question about digital product design, the system searches through my writings, finds and puts the most relevant bits into context for AI models to use and reference, then cities them in the results people see. This is pretty transparent in the interface: the articles, videos, audio, and PDFs used are shown on the right with citations within each response to where these files were used the most.
The most complicated things get in Ask LukeW is when someone opens one of these citied articles, videos, or PDFs to view its full contents. In this case, a small "context chip" is added to the question bar to make clear questions can be asked of just this file. In other words, the file is the primary thing in context. If someone wants to ask a question of the whole corpus of my writings and talks again, they can simply click on the X that removes this context constraint and the chip disappears from the question bar. You can try this out yourself here.
Context chips are pretty common in AI products today because they're a relatively easy way to both give people a sense of what's influencing an AI model's replies and to add or remove it. When what's in context expands, however, they don't scale very well. For example, Augment Code uses context chips for retrieval systems, active files, selected text, and more.
Using a context chip to display everything influencing an AI model's response begins to break down when many things (especially different things) are in context. Displaying them all eats up valuable space in the UI and requires that their names or identifiers are truncated to fit. That kind of defeats the purpose of "showing you what's in context". Also when AI products do automatic context retrieval like Augment Code's context retrieval engine: does that always show up as a chip? or should people not worry about it and trust the system is finding and putting the right things into context?
With AI products using agents these issues are compounded because each tool call an agent makes can retrieve context in different ways or multiple times. So showing every bit of context found or created by tools as a context chip quickly breaks down. To account for this in earlier versions of Bench, we showed the context from tools used by agents as it was being created. But this turned out to be a jarring experience as the context would show up then go away when the next tool's context arrived (as you can see in the video).
Since then, we've moved to showing an agent's process of creating something as condensed steps with links to the context in each step. So people can click on any given steps to see the context a tool either found or created. But that context isn't being automatically flashed in front of them as it's made. This lets people focus on the output and only dig into the process when they want to understand what led to the output.
This approach becomes even more relevant with agent orchestration. When agents can make use of agents themselves, you end up with nested amounts of context. Told you things were a lot simpler two years ago! In these cases, Bench just shows the collective context combined from multiple tool calls in one link. This allows people to examine what cumulative context was created by sub agents. But importantly this combined context is treated the same way - whether it comes from a single tool or a subagent that uses multiple tools.
While making context understood and manageable feels like the right thing to provide transparency and control, increasingly people seem to focus more on the output of AI products and less on the process that created them. Only when things don't seem "right" do they dig into the kinds of process timelines and context links that Bench provides. So if people become even more confident using AI products, we might see context management UIs with even less presence.
What Do You Want To AI?
Alongside an increasing sameness of features and user interfaces, AI applications have also converged on their approach to primary calls to action: "What Do You Want To ___?" But is there a better way... especially for more domain specific applications?
{kind=link}
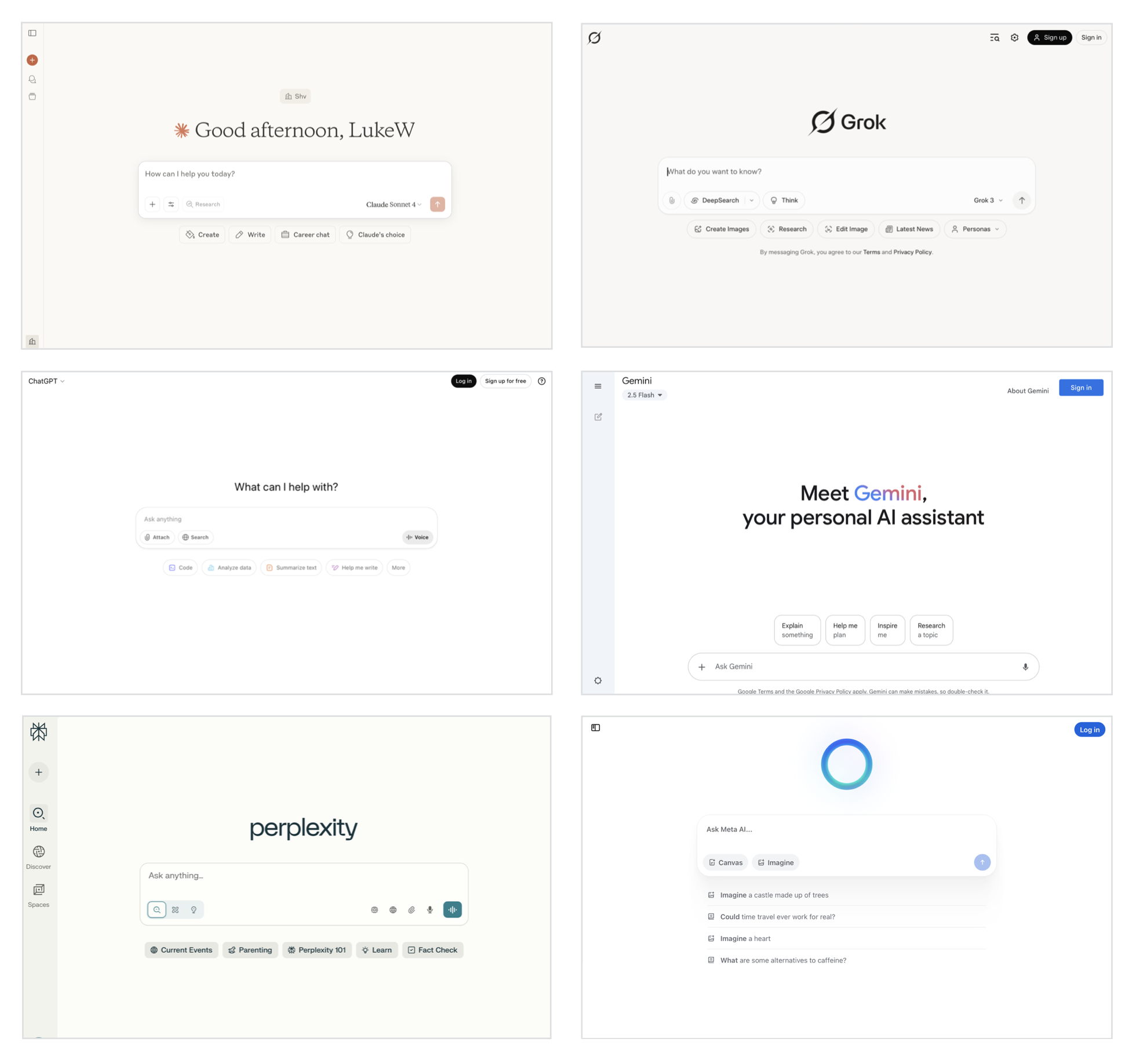
Looking across AI products today, most feature an open-ended text field with an equally open-ended call to action:
- What do you want to know?
- What can I help with?
- What do you want to create?
- What do you want to build?
- What will you imagine?
- Ask anything...
- Ask a question...
- Ask [AI tool]...
So many questions. I've even turned them into a running joke. When a financial company integrates their AI: "What do you want to bank?" or "What do you want to accountant?" Silly I know, but it illustrates the issue. People often don't know what AI products can do nor how to best instruct/prompt them. Questions just exacerbate the issue.
{kind=link}
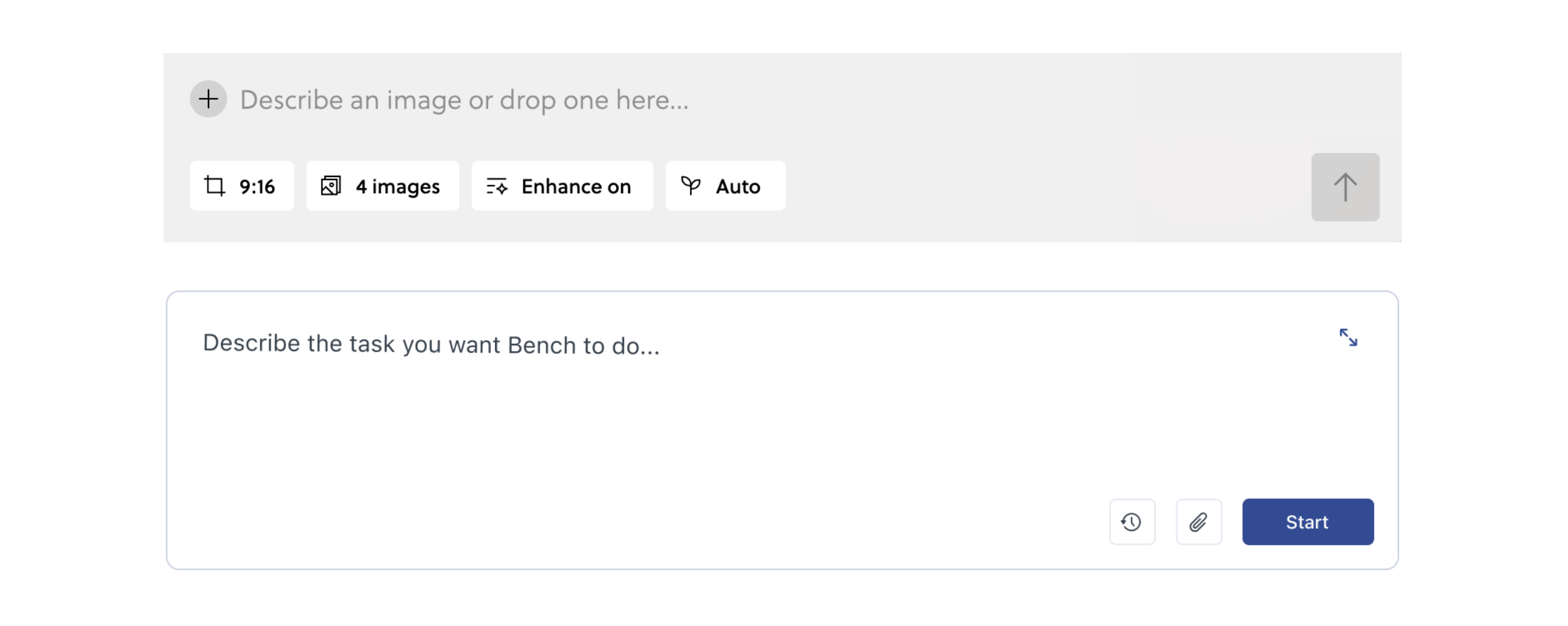
It may be a small detail but instead of asking, how about instructing? Reve's image creation call to action says: "Describe an image or drop one here...". Bench's AI-powered workspace starts with: "Describe the task you want Bench to do...". Both calls to action are still open ended enough that so they can capture the kind of broad intent AI models can handle. But perhaps there's something to having a bit more guidance beyond "What Do You Want To AI?"
What Do You Want To AI?
Alongside an increasing sameness of features and user interfaces, AI applications have also converged on their approach to primary calls to action: "What Do You Want To ___?" But is there a better way... especially for more domain specific applications?
Looking across AI products today, most feature an open-ended text field with an equally open-ended call to action:
- What do you want to know?
- What can I help with?
- What do you want to create?
- What do you want to build?
- What will you imagine?
- Ask anything...
- Ask a question...
- Ask [AI tool]...
So many questions. I've even turned them into a running joke. When a financial company integrates their AI: "What do you want to bank?" or "What do you want to accountant?" Silly I know, but it illustrates the issue. People often don't know what AI products can do nor how to best instruct/prompt them. Questions just exacerbate the issue.
It may be a small detail but instead of asking, how about instructing? Reve's image creation call to action says: "Describe an image or drop one here...". Bench's AI-powered workspace starts with: "Describe the task you want Bench to do...". Both calls to action are still open ended enough that so they can capture the kind of broad intent AI models can handle. But perhaps there's something to having a bit more guidance beyond "What Do You Want To AI?"